Comunidades y herramientas de traducción libres
Artículo publicado en enero de 2012, en el número 9 de la revista Tradumàtica, con el nombre de «Algunas reflexiones sobre la localización comunitaria de software libre». La licencia y el respeto a los plazos de explotación de la versión en papel me permiten republicarlo ahora en versión html, con las adaptaciones lógicas de una versión online. Se corrigen algunos de los errores detectados con posterioridad a la publicación, se han respetado algunas de las correcciones interpares aplicadas y se han revertido otras.
Entrada del 30 de junio de 2012. Enlaces revisados el 12 de marzo de 2023.
Versión pdf, versión local. El estudio, las versiones de las aplicaciones y la redacción son de primavera de 2011.
Estado de la cuestión en primavera de 2011
Resumen
El presente artículo tiene dos objetivos: por un lado presenta los resultados de una investigación sobre qué herramientas libres de apoyo a la calidad en la traducción han aparecido en los últimos años; por otro pretende hacer un sondeo del estado a día de hoy del conocimiento y uso de dichas herramientas, a través del examen de cuáles y cómo son utilizadas por las principales comunidades de traducción del mundo del software libre. Y por los traductores profesionales. En estudios previos pretendíamos detectar una evolución hacia el uso de los formatos y estándares de la industria de la traducción y las herramientas sociales, ¿se ha producido? ¿han seguido evolucionando las aplicaciones libres disponibles o se han estancado? ¿cuál es el estado de salud de los grupos de traductores? ¿explotan suficientemente los recursos tecnológicos disponibles? ¿mantienen criterios de calidad y de completud del flujo de la traducción? ¿se avanza hacia la traducción social? Para tener elementos de juicio, pondremos a prueba el estado de las herramientas para, primero, en el uso clásico, traducir los mensajes y la interfaz de usuario de un programa elegido al azar (el fichero en formato PO de la aplicación de uso creciente en educación ExeLearning) y, en segundo lugar, ver cómo se vertería un documento creado con un editor de textos convencional descargado de la red.
Introducción
Con carácter cíclico el autor ha ido publicando presentaciones más o menos detalladas del mundo de la traducción de software y documentación libres, traducción realizada por comunidades y con herramientas libres. 2004, 2006, 2008... En esos estudios y en varios encuentros hemos abogado por una profesionalización de la labor de traducción, en paralelo a la evidente profesionalización del desarrollo del código libre; no en el sentido de que la tengan que realizar empresas necesariamente, sino de que estén presentes los criterios de calidad del flujo, reflejados en la existencia de normas terminológicas, de estilo, de reutilización de traducciones aceptadas, y el reparto claro de papeles, con traductores voluntarios que se acercan por primera vez, pero también revisores, validadores, etc. ¿Se está produciendo?
También creíamos detectar en los análisis anteriores una evolución hacia una traducción social, posibilitada por la evolución hacia la conectividad permanente pero impulsada por la conciencia creciente de que, como condición de calidad, es necesario homogeneizar las traducciones pertenecientes al mismo proyecto; esta socialización puede manifestarse como terminologías y memorias compartidas, o como el uso de herramientas sociales para la fase de traducción (traducción contra servidor mediante interfaz web, pero también uso de foros o listas de distribución para la organización y el día a día del proceso, dudas, consultas...). ¿Se confirma esta tendencia? ¿Y la del uso creciente de los estándares de la industria de la traducción, TMX, TBX...?
Nos haremos una tercera serie de preguntas: ¿están las herramientas libres de apoyo a la traducción a la altura de las necesidades de los proyectos y de los traductores que quieren utilizar software libre para su trabajo? ¿Permiten realizar el ciclo completo de traducción? Son preguntas ambiciosas. Tenemos 3000 palabras para intentar visualizar respuestas no especulativas, será necesario ser sintéticos.
Un caso real de traducción de interfaz de usuario
Por razones profesionales el autor ha debido utilizar con frecuencia eXeLearning, aplicación destinada a la creación de contenidos educativos. Como la traducción disponible en castellano es manifiestamente mejorable (los errores detectados en la versión existente, se verá de inmediato, se cuentan por cientos), paralelamente a la redacción de este artículo y utlizando las herramientas que en él se analizan, se ha realizado un ensayo de actualización y mejora de la misma. Sirva el detalle del trabajo de corrección y actualización de la traducción de este generador de contenidos como investigación previa sobre el estado y funcionalidad de las herramientas libres de ayuda a la traducción, puestas a prueba en el uso práctico sobre unos textos reales.
En una investigación de detalle con la limitación de espacio de la actual no es posible volver a explicar el flujo de trabajo habitual en la traducción de las interfaces de las aplicaciones creadas con software libre. Diremos que los desarrolladores y traductores disponen de un conjunto de herramientas, gettext, que les permite colaborar, y que los traductores se encuentran las cadenas de texto ya extraídas, en un fichero, de extensión PO, que además puede incluir comentarios del autor, del código de otros traductores o revisores, y referencias al contexto de donde procede el mensaje. El fichero traducido, que contiene las cadenas en las lenguas origen y destino, se incorpora al paquete en el que se distribuirá la aplicación, junto a las traducciones al resto de los idiomas disponibles.
Aunque las fuentes de eXeLearning no son las estándar de un aplicación libre (es una mezcla de html, XML, python y XUL, mientras que lo habitual es traducir código C o java) sí usa los formatos estándar para su localización (PO: Portable Object). Aunque hemos dicho que lo habitual es que el traductor reciba un fichero PO con los últimos cambios y añadidos en las fuentes, y sobre el que deberá trabajar, por completud en esta investigación hemos procedido a realizar una comprobación previa: descargar las fuentes completas de eXeLearning, actualizadas con el último fichero POT (Portable Object Template) generado automáticamente —el traductor nunca se encarga de esto— y con el fichero PO con la traducción española. ¿Qué se puede averiguar sobre este fichero con las herramientas disponibles? ¿corresponde al último POT? ¿está traducido en su totalidad? ¿quién lo ha traducido? ¿esa persona se siente aún responsable de seguir manteniendo la traducción?
Vayamos por partes: ¿es una traducción actualizada? Usemos fechas, por precisión y claridad, en el nombre del fichero PO; aplicaremos en primer lugar las herramientas estándar, las incluidas en gettext, sobre exe_es_20110310.po. Msgfmt nos devuelve información sobre un fichero (en este caso queremos saber cuántas cadenas están traducidas)
$ msgfmt --statistics -c -v -o /dev/null exe_es_20110310.po exe_es_20110310.po: 690 mensajes traducidos, 20 traducciones difusas. $ msgmerge -o exe_es_20110420.po -i -w 79 exe_es_20110310.po messages.pot $ msgfmt --statistics -c -v -o /dev/null exe_es_20110420.po exe_es_20110420.po: 690 mensajes traducidos, 20 traducciones difusas.
Msgmerge actualiza el fichero de traducciones al español con las nuevas cadenas por traducir de las fuentes, si las hay (creamos exe_es_20110420.po), msgfmt comprueba el estado del fichero resultante: en ambos casos hay 20 traducciones fuzzy, cadenas con coincidencias difusas, creadas automáticamente por el sistema cuando encuentra cadenas nuevas con pocas diferencias con cadenas traducidas y que quedan marcadas para su revisión por el traductor; no hay cadenas sin traducir. Parece que el fichero original español estaba al día (podemos prescindir de exe_es_20110420.po), pero se trata de una traducción incompleta o sin revisar.
Hay aplicaciones, como pocount, del Translate Toolkit, que nos dan más información:
$ pocount exe_es_20110310.po exe_es_20110310.po type strings words (source) words (translation) translated: 690 ( 97%) 5252 ( 98%) 5512 fuzzy: 20 ( 2%) 106 ( 1%) n/a untranslated: 0 ( 0%) 0 ( 0%) n/a Total: 710 5358 5512
El paquete experimental Pology proporciona posieve, aún más informativo, como puede apreciarse en la imagen

Esto, salvo la salida silenciosa de msgfmt, son estadísticas, ¿pueden las herramientas darnos más información? ¿por ejemplo de la validez y corrección del fichero PO? POFileChecker, de gettext-lint,
$ POFileChecker exe_es_20110310.po > exe_es_20110310_errores.xml
nos devuelve un fichero xml donde se señalan más de 50 errores, entendiendo por errores diferencias entre la versión original y la traducida como
<error line="323" message="45">missing .</error> <error line="347" message="48">extra </error>
Que falte un punto al final de una frase y que en la versión castellana haya un salto de línea de más tienen que ver con la calidad de la traducción, pero no son los errores más importantes que podemos buscar, ¿cierto? Nos quedan varios campos que sería interesante cubrir antes de proceder a la traducción humana del fichero: ¿es ortográficamente correcto? ¿y estilísticamente? ¿Podemos examinar su ortografía? No parece tarea fácil, dada la mezcla de idiomas, etiquetas, referencias a las fuentes, etc. Vamos a echar un vistazo al funcionamiento de pofilter
$ pofilter --language es-ES --input=exe_es_20110310.po --output=exe_es_20110310_pofilter_errores.po
Ejemplos de salida
# (pofilter) startwhitespace: checks whether whitespace at the beginning of the strings matches # (pofilter) spellcheck: check spelling of applet (could be aplegar / apaleo / pletina / repletar), check spelling of seleccionelo (could be selecciónelo / seleccione lo / seleccione-lo)
El sieve para posieve check-spell-es nos hace un trabajo más específicamente ortográfico (con la colaboración de enchant y de los proveedores de diccionarios ortográficos aspell, ispell o myspell):
$ posieve -s lang:es check-spell-ec exe_es_20110310.po
Devuelve un fichero de 53.3kB con líneas como
exe_es_20110310.po:22(#1): Unknown word 'Geogebra' (suggestions: Geografía, Geográfica, Geogonía, and Geometral). exe_es_20110310.po:66(#6): Unknown word 'palaras' (suggestions: palearas, parlaras, paliaras, palabras, palparas...).
Geogebra no es reconocida como palabra castellana, correcto, y «palaras» es una evidente errata que hay que corregir.
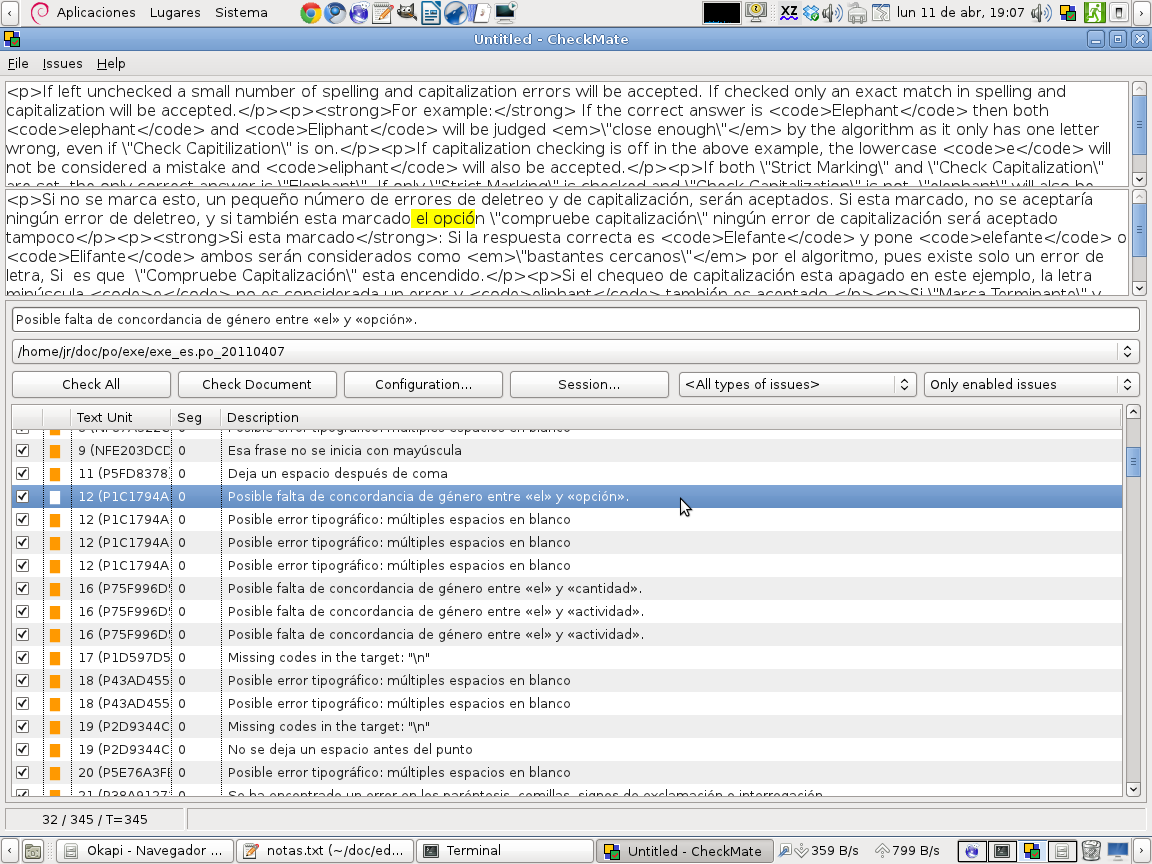 Hemos demostrado la existencia y eficacia de las herramientas ortográficas específicas; ¿y estilísticas? Pues ya sí, al fin. La imagen nos muestra un ejemplo de uso de LanguageTool como aplicación autónoma (el uso más común es como módulo para Libre/OpenOffice). Por un lado nos da una información similar a la de pofilter, por otro lado aplica reglas estilísticas editables, genéricas y específicas para cada lengua.
Hemos demostrado la existencia y eficacia de las herramientas ortográficas específicas; ¿y estilísticas? Pues ya sí, al fin. La imagen nos muestra un ejemplo de uso de LanguageTool como aplicación autónoma (el uso más común es como módulo para Libre/OpenOffice). Por un lado nos da una información similar a la de pofilter, por otro lado aplica reglas estilísticas editables, genéricas y específicas para cada lengua.
Creemos que va quedando demostrada la afirmación anterior de que el fichero exe.po necesitaba algo de trabajo, ¿podemos averiguar algo más de sus problemas antes de ponernos con él? Pues sí, LanguageTool tiene una característica que lo hace aún más interesante: puede quedarse residente, como un demonio, y puede llamarse a sus funciones desde otras aplicaciones. OmegaT puede utilizar la información de errores que proporciona, pero antes veremos el funcionamiento de Checkmate, definida como «an application to perform quality checks on bilingual files», justo lo que buscábamos.
La captura
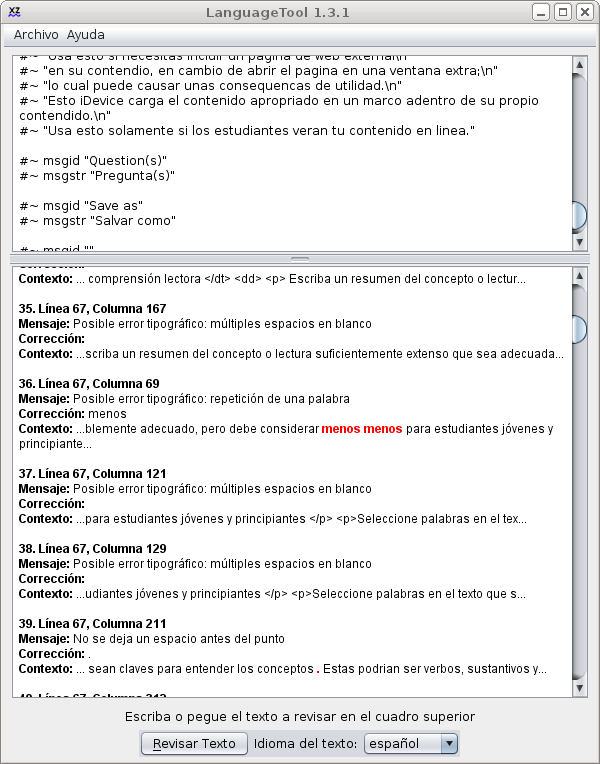
nos muestra la salida de Checkmate sobre nuestro pobre fichero, y en la figura
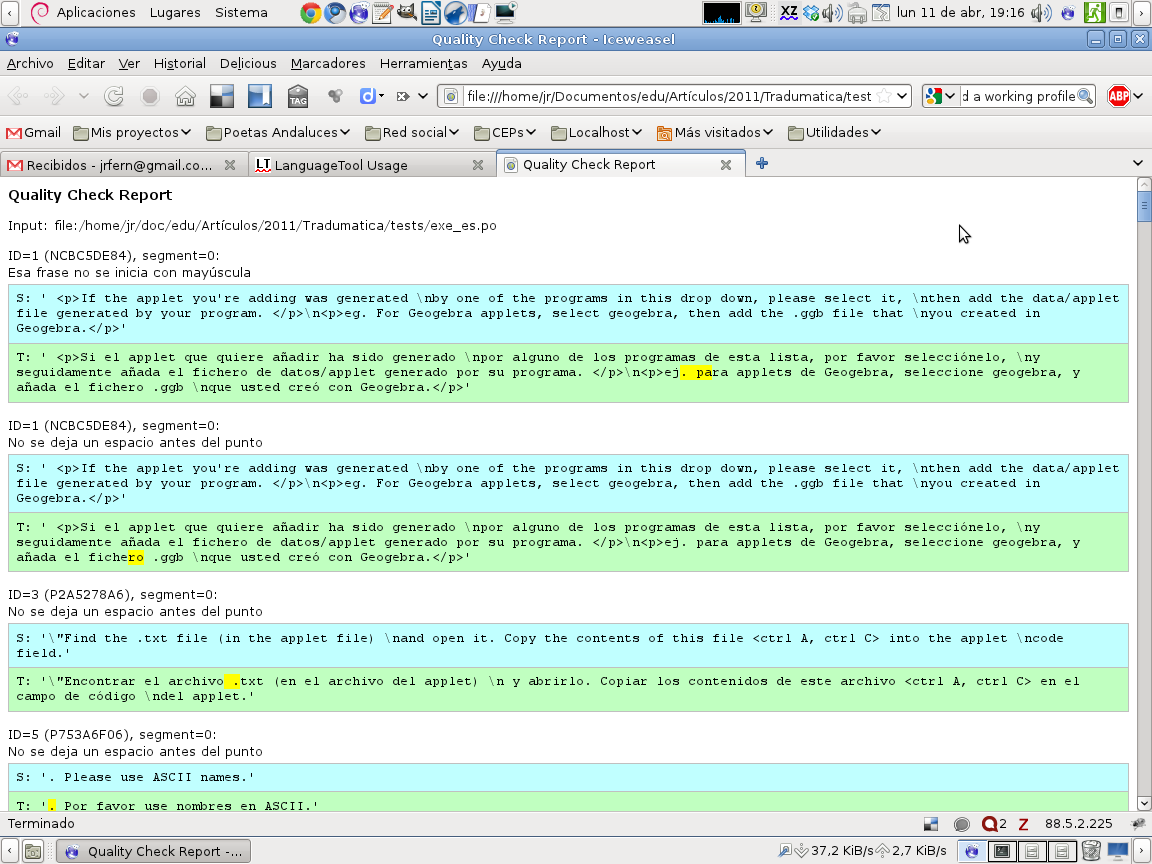
vemos que los datos pueden exportarse a formato html para su publicación o consulta. Finalmente la siguiente imagen
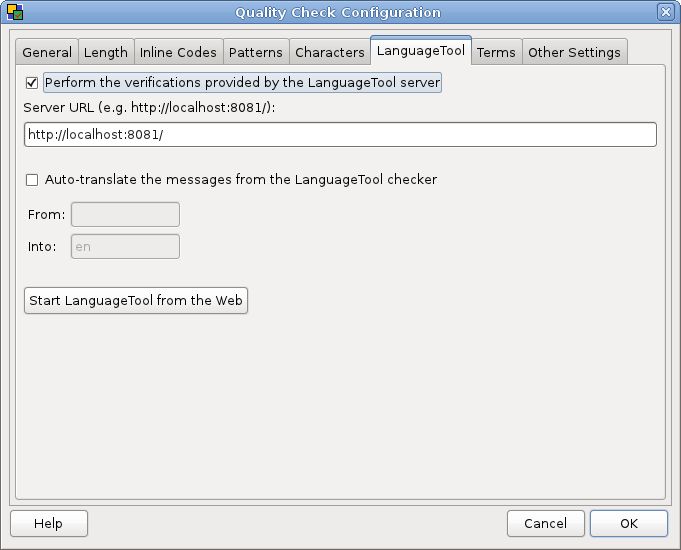
muestra que Checkmate es configurable para que, además de sus propias comprobaciones de calidad, aplique los tests de LanguageTool. Que una herramienta automática encuentre errores del tipo de “el opción” nos parece un éxito de programación.
Nuestro documento tiene decenas de errores ortográficos y estilísticos, ¿Podemos ayudar a corregirlos? ¿Estamos autorizados y por otro lado se recibirá positivamente la contribución? Poder podemos, es software libre. Pero queremos que el autor lo acepte, y que no haya otra persona o grupo responsable del dominio (como en el Proyecto de Traducción). ¿Quién o quiénes lo han traducido anteriormente? Esa información está o debe de estar en la cabecera.
"Last-Translator: Asociacion Cultural Reggae <acreggae@acreggae.com>"
Tras ponernos en contacto con la asociación (correo 11 de abril de 2011), han respondido
Creo recordar que uno de nuestros compañeros estuvo hace tiempo traduciendo algo. Pero lo que es seguro que ahora no lo está haciendo, por lo que no hay problema de que os piséis.
Hay otra entrada de la cabecera que resulta significativa:
"X-Generator: Pootle 1.1.0"
¡El fichero se escribió utilizando el ya difunto servidor Pootle de eXeLearning! Aprovechemos para adelantar la siguiente hipótesis de trabajo, que deberá ser confrontada con la realidad: las herramientas de traducción social tienen sentido si están supervisadas por un equipo que vigila y homogeneiza el resultado final, y este equipo sólo es posible con proyectos que superan un determinado tamaño. El uso de un servidor pootle sin un equipo detrás que revise la calidad de la traducción tiende a producir traducciones incompletas, precipitadas, fragmentadas e inconexas. Volveremos sobre esto más adelante.
Hasta ahora hemos demostrado únicamente que era necesaria una nueva traducción del fichero PO, y que ahora se dispone de herramientas que ayudan a revisar y mejorar la ortografía y el estilo, detectando los errores más comunes, y a comprobar que el traductor no introduce errores en la traducción, mediante la comparación entre las propiedades técnicas (saltos de línea, espacios, parámetros...) del texto original y del destino. Ahora hay que hacer la traducción: ¿en la nube o local? ¿con qué aplicación? ¿siguiendo qué guías terminológicas y estilísticas? ¿reutilizando qué memorias de traducción? Hagamos un alto en nuestro proceso y veamos qué se está usando en el mundillo.
Momento actual de las comunidades de traducción
Nota para lectores ajenos al mundo del software libre. No sabemos si se ha preguntado usted quién ha traducido la interfaz de usuario del firefox o el vlc que quizás use; quizás le sorprenda averiguar que es bastante probable que hayan sido traducidas por una comunidad de voluntarios a lo largo de varios años.
El tema de quién ha traducido qué es ligeramente complejo, porque una aplicación llega a los usuarios finales en una estructura que tiene capas. Supongamos que alguien escribe un programa nuevo. Normalmente se escribirá con la interfaz de usuario en inglés, el idioma común —es posible que aquí aparezca ya la primera traducción, si el inglés no es la lengua materna del autor—, y puede que esa persona busque en la red voluntarios que le traduzcan esos mensajes a distintos idiomas; puede, incluso, que el autor (que puede ser una empresa o una organización privada o pública) instale en su servidor un programa que ayude a traducir por trozos. Ocurrirá a veces que una empresa o entidad encuentre utilidad en la aplicación, y encargue la traducción, por supuesto sólo para el idioma nativo. Pero es posible también que los autores conozcan el Proyecto de Traducción Libre y acudan en busca de ayuda y estructura a los cientos de traductores que han renunciado a sus derechos sobre las traducciones y se responsabilizan de traducir y actualizar traducciones de las aplicaciones que adoptan. Caso distinto es que la aplicación se haya construido usando las bibliotecas GTK/GNOME o QT/KDE, y se integre dentro de estos marcos; lo normal entonces es que fuera traducida por los equipos de traductores de GNOME o de KDE. Puede ser también que una utilidad de uso no generalista (pensemos en las educativas por ejemplo) haya pasado desapercibida y llegue sin traducir a una de las distribuciones básicas, Debian, Fedora, Ubuntu... puede ser incluso que una derivada de estas se vea en la obligación de enfrentarse a la tarea. Esto no es raro; de hecho es muy común en las distribuciones educativas que se crean en nuestro país, tengan o no lengua propia, ¿quién va a usar en la escuela tal o cuál recurso si no está disponible en la lengua o lenguas locales? En MAX, la distribución educativa de Madrid, se traducen aplicaciones; en Guadalinex, la andaluza, también, y en Linex (Extremadura)... Por supuesto este esfuerzo es masivo en las distribuciones GNU/Linux de comunidades con lengua propia.
La multiplicidad de orígenes descrita puede causar problemas. Es posible que se traduzcan cosas de forma paralela, porque es difícil que la traducción ascienda por la jerarquía de vuelta hacia mainstream, entre otras cosas porque en las derivadas se suele trabajar con versiones estables, que pueden tener hasta un par de años, y en los proyectos está la versión en desarrollo, con sus cambios, cadenas nuevas, etc. Además históricamente no solía haber preocupación por devolver el trabajo a la comunidad, la perspectiva acababa en los destinatarios directos (alumnado, profesorado regional); incluso es habitual hacer cambios en el código que se quedan en los repositorios locales y a veces ni se hacen públicos.
Antes de examinar qué usan, recordemos qué hacen los grupos de traductores voluntarios. El Free Translation Project fue revivido en 2007 por Benno Schulenberg y se mudó del DIRO de la Universidad de Montréal a Holanda, a Vrijschrift.org. Podemos leer en su matriz que el número de dominios textuales bajo el Proyecto traducidos parcial o totalmente al castellano es de 126. Están por supuesto las aplicaciones básicas del proyecto GNU y muchas otras, que aprovechan los servicios que proporciona el Proyecto.
Damned Lies es el nombre del sitio donde se coordina la internacionalización de GNOME. Ahí podemos ver que la interfaz de usuario de la versión estable (3.0) está traducida al 100% al castellano y al gallego, al 99% al catalán, al 97% al vasco y 81% al asturiano. ¡Hablamos de 39791 cadenas de texto!

Similares cifras encontramos para KDE:
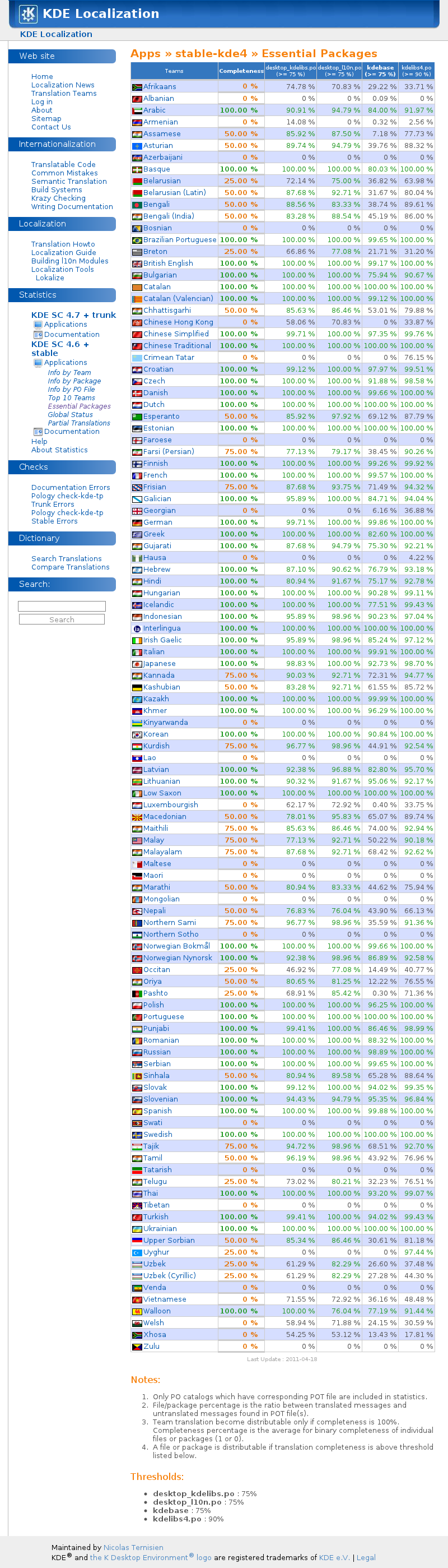 117588 cadenas, de las que se han traducido para la versión estable (4.6), los siguientes porcentajes de los llamados paquetes esenciales: castellano, gallego, catalán, vasco: 100%; asturiano: 50%. No sé si el lector se hace una idea de la carga de trabajo acumulado y complementario que se realiza por estos equipos, y del coste que tendría en un proyecto comercial privativo. ¿Cómo lo consiguen?
117588 cadenas, de las que se han traducido para la versión estable (4.6), los siguientes porcentajes de los llamados paquetes esenciales: castellano, gallego, catalán, vasco: 100%; asturiano: 50%. No sé si el lector se hace una idea de la carga de trabajo acumulado y complementario que se realiza por estos equipos, y del coste que tendría en un proyecto comercial privativo. ¿Cómo lo consiguen?
Volvamos a la pregunta que nos hacíamos: ¿cómo funcionan en primavera de 2011 los equipos de traductores voluntarios? Durante la fase de preparación previa de este artículo encontramos un documento de gran ayuda, http://live.gnome.org/TranslationProject/Survey, que nos informaba de la encuesta que Gil Forcada había enviado a los equipos de internacionalización de GNOME, preguntándoles cosas como el número de miembros de los equipos, cómo se coordinan, qué herramientas usan para ayudarse en la traducción, cómo cuidan el flujo de trabajo, qué echan de menos... Si en GNOME habían tenido la idea de hacer una encuesta entre sus grupos de traducción, ¿por qué no reenviar por correo las preguntas a los coordinadores de los grupos de los otros proyectos de traducción al español? Como era de esperar —esto es software libre, luego cercano— un porcentaje respondió, y tenemos datos sobre cómo están organizados, qué herramientas utilizan y cómo es su flujo de trabajo (existe además una encuesta similar en el wiki de Ubuntu: Teams Health Check). Sinteticemos las respuestas.
¿Cómo se organizan los equipos y cuántos miembros tienen? Todos se caracterizan por tener un núcleo duro, de entre 5 y 10 miembros, que comparten criterios y experiencia, y una cifra variable de gente de paso, que se queda en el proyecto en un pequeño número. Jorge González, de GNOME, nos cuenta (en varios intercambios de correo en abril de 2011) que usan fundamentalmente gtranslator y kbabel. Eloy Cuadra responde (abril de 2011), en nombre de KDE, que usan Lokalize y comprobaciones automáticas con pology y su interfaz gráfica KSvnUpdater. Según la encuesta de Ubuntu se trabaja preferentemente vía web, sobre Launchpad. En Sugar, etoys y en OpenOffice se sigue usando pootle. No hemos oído a nadie mencionar XLIFF ni las aplicaciones para trabajar con este formato. Eso en cuanto a herramientas.
Las memorias de traducción ambos equipos las construyen a mano. En GNOME «actualmente no trabajamos con .TBX ni .TMX. Generamos las memorias de traducción a partir de los archivos po de Damned Lies, y los importamos en Gtranslator y kbabel (que tiene sqlite, por lo que el archivo acaba siendo un .db)». Parecido en KDE: «por ahora cada miembro usa su propia memoria de traducción (MT). El programa que usamos para traducir (Lokalize) se encarga de manejarla. Pero tengo en proyecto usar una MT común para todos los miembros del equipo». Sorpresa: en Debian se genera de forma automática un compendio PO de las traducciones a cada idioma. Descargamos el fichero español: pesa 72.9 megas.
¿Y la terminología? ¿Alguna noticia? Ya hemos leído que los proyectos no comparten TBX. «Estamos en proceso de creación de un glosario nuevo», nos dicen desde GNOME. «Probablemente partamos del de Serrador (ver la referencia en la bibliografía, se trata de un documento de 2006), quizá probemos el glosario en línea de Lucas Vieites». Con posterioridad a la publicación de la versión en papel del artículo recibí un correo de Jorge González (con fecha de 9 de enero de 2012) con el siguiente enlace a un glosario ya en uso: ¡una hoja de cálculo de gdocs! En la documentación proporcionada en UbuntuSpanishTranslators descubrimos una herramienta interesante, OpenTran.eu
( 2012
2012
![]() 2023), que recopila las terminologías de los principales proyectos (KDE, GNOME, Fedora, OpenOffice, OpenSuse, Mandriva, Mozilla, Debian Installer...), permite la consulta en línea de términos y expresiones y devuelve ejemplos de cómo se han traducido.
2023), que recopila las terminologías de los principales proyectos (KDE, GNOME, Fedora, OpenOffice, OpenSuse, Mandriva, Mozilla, Debian Installer...), permite la consulta en línea de términos y expresiones y devuelve ejemplos de cómo se han traducido.
¿Y las validaciones de los ficheros PO y el control de calidad? En KDE «ejecutamos sieves de Pology con los que verificamos la validez de los archivos PO, el uso de nuestro glosario, reglas gramaticales de nuestro idioma y forzamos el uso de comillas españolas en lugar de las inglesas». En GNOME el control de calidad, revisiones, etc. es un proceso manual que se hace por los componentes del núcleo duro.
El otro lado del océano
La interfaz de usuario no es el único tipo de texto al que se va a enfrentar un traductor. Los traductores de software libre se encuentran con documentos complejos, guías, tutoriales, ejemplos. Los porcentajes de completud de las traducciones de este tipo de textos no se acercan a los de los mensajes de usuario (basten como muestra las estadísticas de KDE. Asturiano y vasco: 0%; gallego: 25%; catalán: 47%; castellano: 90%). En primer lugar porque se considera que la documentación es menos importante, menos urgente al menos, es necesario buscarla para leerla y los mensajes saltan en la pantalla, son intrusivos y no pueden ignorarse; posiblemente también que porque se desconocen las herramientas adecuadas y porque es más difícil trabajar por trozos sin tales herramientas. Estamos convencidos de que aquí es donde la tecnología de la traducción es más necesaria y tiene más oportunidades de ayudar. Un texto largo debe ser segmentado para que las memorias de traducción puedan encontrar coincidencias. Debe disponerse de glosarios y memorias, que aconsejan, reutizan y ahorran tiempo y esfuerzo. Y debe poderse convertir el texto de y al formato de documento final sin pérdida de información, sea cual sea el formato que utilicen las herramientas de traducción internamente, PO, XLIFF o TMX.
Hicimos, simultáneamente al del de los equipos de traducción clásicos de software libre, un sondeo informal en twitter sobre qué herramientas libres usaban los traductores profesionales. De nuevo sintetizamos en una las respuestas: «He utilizado Okapi tools, Open Language Tools, Foreign Desk, PoEdit, Anaphraseus... pero fundamentalmente OmegaT. Los formatos no son problema, los paso a .odt y listo, ningún problema de compatibilidad. El problema con TMX, TBX compartidas es que los derechos de autor son en parte del cliente y lo de la confidencialidad dificulta la cosa». Nadie habla de PO. Tampoco de XLIFF.
Deducción: sigue existiendo el abismo entre las dos tradiciones, entre la que procede de traducir las interfaces de usuario de las aplicaciones de software libre y la que básicamente traduce documentos de texto. No usan herramientas comunes, ni formatos: unos siguen convirtiendo a PO, los otros reciben ficheros DOC. El tema de las memorias de traducción y de los glosarios compartidos es un tema interno al proyecto o a la empresa, y normalmente son construcciones personales, que tienen que ver con el enriquecimiento de los recursos privados (no digo privativos) producido por la veteranía, más que un proceso colectivo e intencionado.
Con el conocimiento de este punto de partida hemos procedido a comprobar que las herramientas de ayuda también son aplicables al trabajo con los filtros y las herramientas de traducción de textos abiertos, específicamente con Lokalize y con OmegaT. En la figura
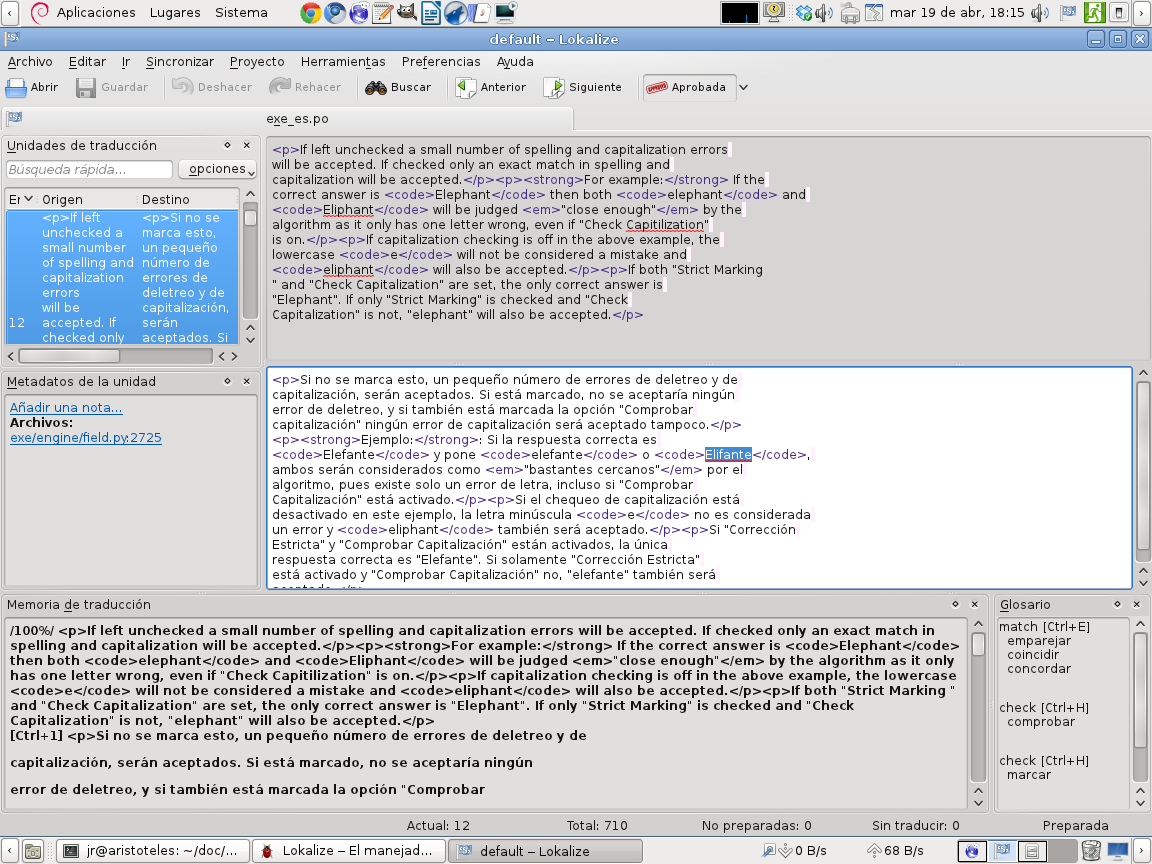
tenemos un ejemplo de uso de Lokalize con las herramientas auxiliares instaladas: diccionario, memoria, glosario; en esta captura de pantalla
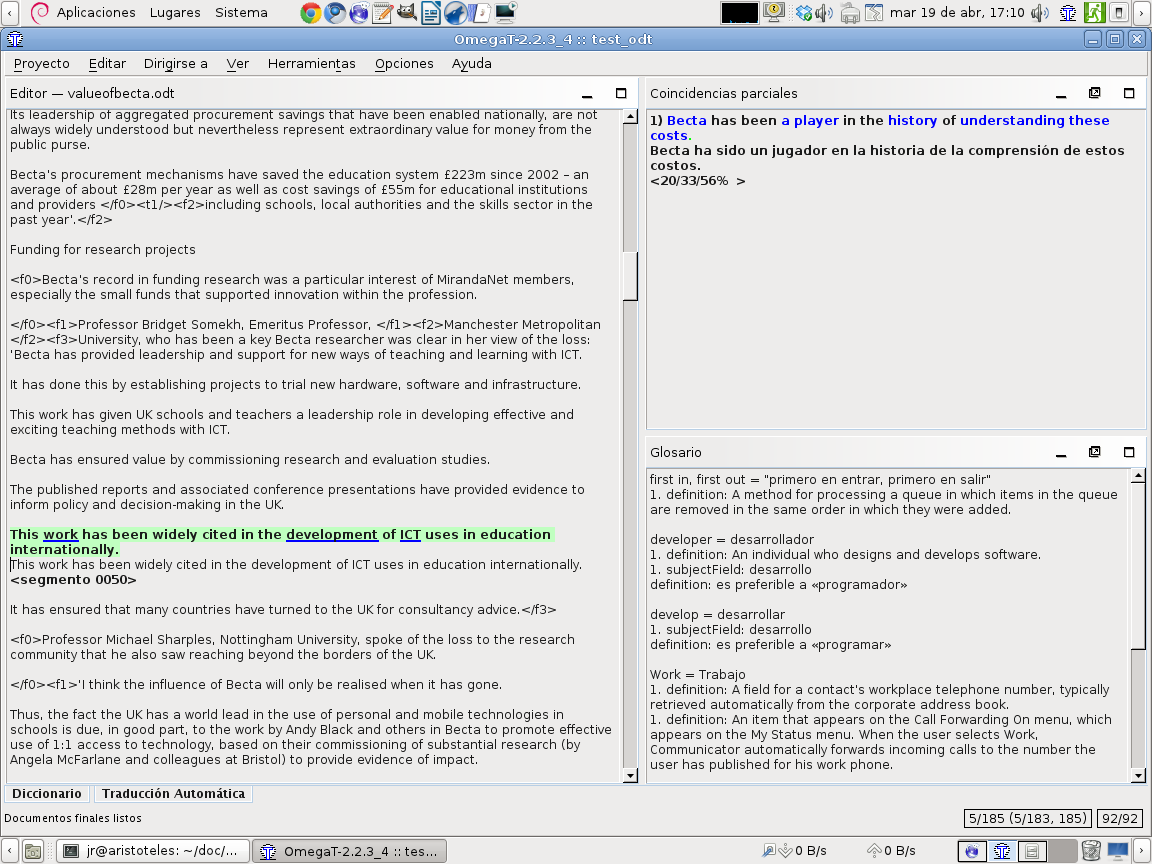
vemos OmegaT con diccionario, glosario, filtros extra...
Conclusiones
Han aparecido herramientas eficaces que ayudan a mejorar la calidad de la traducción. Estas herramientas se pueden aplicar tanto a la tarea tradicional de traducir la interfaz de usuario como a la de traducir textos abiertos. Para las dos tareas, y sin que exista hoy día una justificación salvo la historia, se han desarrollado estrategias y tradiciones muy distintas. Esta separación de mundos nos debe llevar a la reflexión. Es hora de dar el giro final en la marcha de este artículo y de cambiar de preguntas. Ya no nos interesa qué usan, sino qué podrían usar nuestros equipos. Pasar de la investigación a la acción. Y, como venimos insistiendo desde hace años, no se trata de la aplicación o de los formatos, la clave está en el sistema completo de traducción: en el conocimiento de las personas sobre el flujo global del proceso, y en el conocimiento compartido y homogeneizado en acuerdos y estilos, diccionarios, correctores gramaticales y ortográficos, glosarios y memorias. El abanico de aplicaciones especializadas y libres para la traducción de ficheros PO, XLIFF o TMX es amplio; las limitaciones de espacio nos impiden examinar una a una las virtudes y defectos de traducir en la nube con pootle, transifex o el launchpad de Ubuntu, o bien localmente con virtaal, poedit, gtranslator, lokalizer, omegat o emacs en modo po. Y, sin embargo, esa no es la clave. La clave la apuntaba Silvia Flórez, cuando afirmaba que la instalación completa y el uso eficaz de cualquiera de estas aplicaciones (se refería concretamente a OmegaT) estaba dejando de ser trivial. Creemos que el futuro próximo va por ahí: una aplicación especializada, que integre bases de datos locales y remotas de conocimiento acumulado, y filtros conversores de calidad. Todo por supuesto sometido a una revisión experta que asegure la calidad y la cohesión de los resultados.
Una humilde observación final: están los traductores tan ocupados cumpliendo plazos, que no tienen tiempo de investigar para ahorrar tiempo y esfuerzo.
Bibliografía
Fernández García, J.R. (2006a). La traducción del software libre. Una oPOrtunidad de colaborar, Linux Magazine, 19.
Fernández García, J.R. (2006b). La traducción del software libre. Los problemas de PO y el abrazo fuerte, Linux Magazine, 20.
Fernández García, J.R. (2006c). La traducción del software libre. Memorias compartidas, Linux Magazine, 21.
Fernández García, J.R. (2006d). “La traducción del software libre. ¿El momento de cambiar de herramientas?, Linux Magazine, 22.
Fernández García, J.R. (2007). La traducción del software libre. Cerrando el ciclo, Linux Magazine, 23.
Fernández García, J.R. (2008). Fundamentos de tecnología de la traducción. Un repaso a las herramientas de traducción libres, Encuentro G11n para la localización del software al gallego, Santiago de Compostela.
Fernández Serrador, Francisco Javier, et al. (2006) “Localización de GNOME al español”. La localización clásica de este documento ha dejado de existir, aunque se trata de un documento fácilmente localizable en internet a través de sus réplicas. Última consulta en línea, en https://mail.gnome.org/archives/gnome-es-list/2011-October/pdfm6xxph1jsZ.pdf, 2023-03-12.
Flórez, Silvia, laRusalka (2010-05-12) Traducción y mundo libre. ¿Cómo utilizar los plugins de OmegaT?
(2010
![]() 2023)
2023)
GNOME Damned Lies (Malditas Mentiras), lugar donde se centraliza la coordinación de la internacionalización y localización de las aplicaciones del proyecto GNOME.
Vieites, Lucas. Glosario en línea
(2011
![]() 2023).
2023).
Aplicaciones utilizadas y su versión
Gettext: msgmerge, msgfmt (usado paquete Debian, versión 0.18.1).
Gettext-lint: POFileChecker. Fuente: http://gettext-lint.sourceforge.net/ (usado paquete Debian). Latest version: 0.4.0 (2007-02-09). Autores: Pedro Morais, José Nuno Pires, João Miguel Neves.
KSvnUpdater http://www.eloihr.net/ksvnupdater/, de Eloy Cuadra. Interfaz gráfica para el uso de pology.
LanguageTool, 1.3.1 y 1.4, de Daniel Naber http://www.languagetool.org/. Empleo como aplicación independiente, explicado en
http://www.languagetool.org/usage
(2011
![]() 2023).
2023).
Lokalize en paquete Debian 4:4.6.3-1 http://l10n.kde.org/tools/, la herramienta de traducción de KDE
Okapi Framework: CheckMate, Rainbow, Tikal, Ratel. De Yves Savourel, versiones 0.11 y 0.12. http://okapi.opentag.com/ y https://groups.google.com/g/okapi-users.
OmegaT 2.2.3 update 4 y 2.3.0. http://www.omegat.org.
Open-Tran.eu OpenTran.eu
(2011
![]() 2023)
2023)
Pology: posieve http://techbase.kde.org/Localization/Tools/Pology. Uso versiones del subversion de kde. Las fuentes hablan de una initial release 0.10 (Eloy Cuadra me había dado este enlace para pology; http://pology.nedohodnik.net/doc/user/en_US/).
Translate Toolkit: pocount, pofilter, poterminology (usado paquete Debian, 1.7.0-0.1). Emparentados están Pootle, disponible paquete Debian de 2.0.5-0.3, y Virtaal 0.6.1-0.1 y 0.7.0.