Aunque no seamos programadores, hay una gran oportunidad de contribuir en los campos de la documentación y de la traducción. Por una vez querer es poder, ¿queremos ser miembros activos de la comunidad? Por Juan Rafael Fernández García.
| Historial de versiones | ||
|---|---|---|
| Revisión 0.1 | 2006-12-01 | jrf |
| Primera versión CC 2.0 del artículo de Linux Magazine. | ||
Está usted leyendo Una oPOrtunidad de colaborar, primero de una serie de cinco artículos sobre la traducción en el mundo del software libre publicado por primera vez en el número 19 de la revista Linux Magazine, de septiembre de 2006 (pero escrito en julio de 2006). La versión pdf del artículo puede descargarse en el enlace http://www.linux-magazine.es/issue/19/.
La versión «canónica» del artículo, la única mantenida por el autor, se encuentra en http://people.ofset.org/jrfernandez/edu/n-c/traducc_1/index.html. Está publicada por contrato con la editorial bajo licencia Creative Commons Reconocimiento-NoComercial-CompartirIgual 2.0 (-sa-by-nc 2.0).
Índice de la primera parte
I. De la importancia del esfuerzo realizado
II. Repasando: Internacionalización y Localización
III. Ficheros PO y ficheros MO
IV. Anatomía de un fichero PO
V. La herramienta de los traductores:
kbabel
VI. Y en el próximo número...
Cuadro 1: Historia de gettext
Imágenes
Notas
Los problemas de PO y el abrazo fuerte
(Segunda parte del artículo)
Memorias compartidas
(Tercera parte del artículo)
¿El momento de cambiar de herramientas?
(Cuarta parte del artículo)
Cerrando el ciclo
(Quinta parte del artículo)
Referencias a los artículos sobre
traducción
Cuando soñábamos con una implantación masiva del software libre uno de las campos que creíamos que podía tener un desarrollo más fluido era el de la traducción: imaginábamos con ingenuo sentido común que en las escuelas de traducción los estudiantes practicarían haciendo traducciones necesarias además de continuar con los mismos artificiales ejercicios de siempre, y que los profesores de idiomas se lanzarían encantados a colaborar en algo en lo que al fin tienen (tenemos) algo que aportar.
Sin embargo es curioso cómo nos hemos instalado en la cultura de la queja y el fatalismo. ¿Algo no está traducido? «Que me lo traduzcan», dicen los más positivos; comparten con los fatalistas la tendencia a la pasividad. «Pues es que esto será así», piensan los fatalistas resignados, como cuando tienen que reformatear cierto sistema operativo con tendencia a ser caldo de cultivo de virus; o bien, para los fatalistas de lo fatal, «esto del software libre no funciona» cada vez que a ellos algo no les funciona. Pues bien, si algo no funciona o no está traducido, puede ser porque como usuarios no hayamos sabido hacerlo funcionar o actualizarlo a una versión traducida, pero también puede ser que la aplicación esté mal, incompleta... y es bastante posible que nadie se haya ofrecido para traducirla. ¿Por qué no lo hacemos nosotros?
En esta nueva serie de artículos exploraremos las herramientas a nuestra disposición, conoceremos a los principales equipos de traducción al castellano, y señalaremos también los problemas no resueltos. ¿Qué necesitamos para poder seguir de forma práctica esta primera entrega? En nuestro sistema deberán estar instalados los siguientes paquetes: gettext, kbabel (recuerden: aptitude install gettext kbabel). Deberemos tener también ante nosotros algún fichero en formato PO para poder estudiarlo; podemos descargar cualquiera de http://l10n-status.gnome.org/HEAD/es/fifth-toe/index.html por ejemplo.
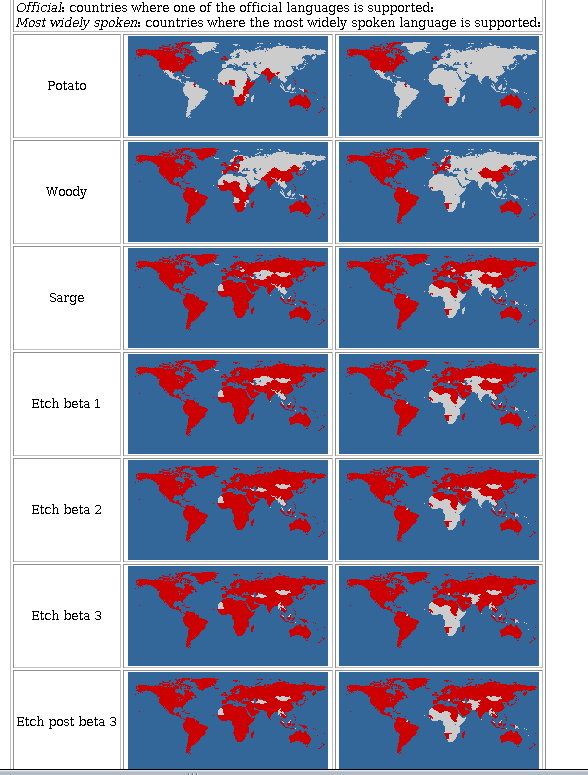
Quizás no tengamos una conciencia clara del esfuerzo que realizan los traductores desinteresadamente. Unos pocos ejemplos pueden ayudarnos a hacernos una idea[1]. Primer ejemplo: en estos momentos se está trabajando en el desarrollo de una nueva versión del instalador de Debian, que deberá poder ser utilizado en el mayor número posible de lenguas. La imagen 1 nos muestra la evolución del número de idiomas en los que puede trabajarse durante la instalación (las tres columnas corresponden a la versión de Debian, países en los que al menos una de las lenguas oficiales están cubiertas y países en los que está cubierta la lengua más hablada). Listos para la dominación del mundo, va a ser verdad.
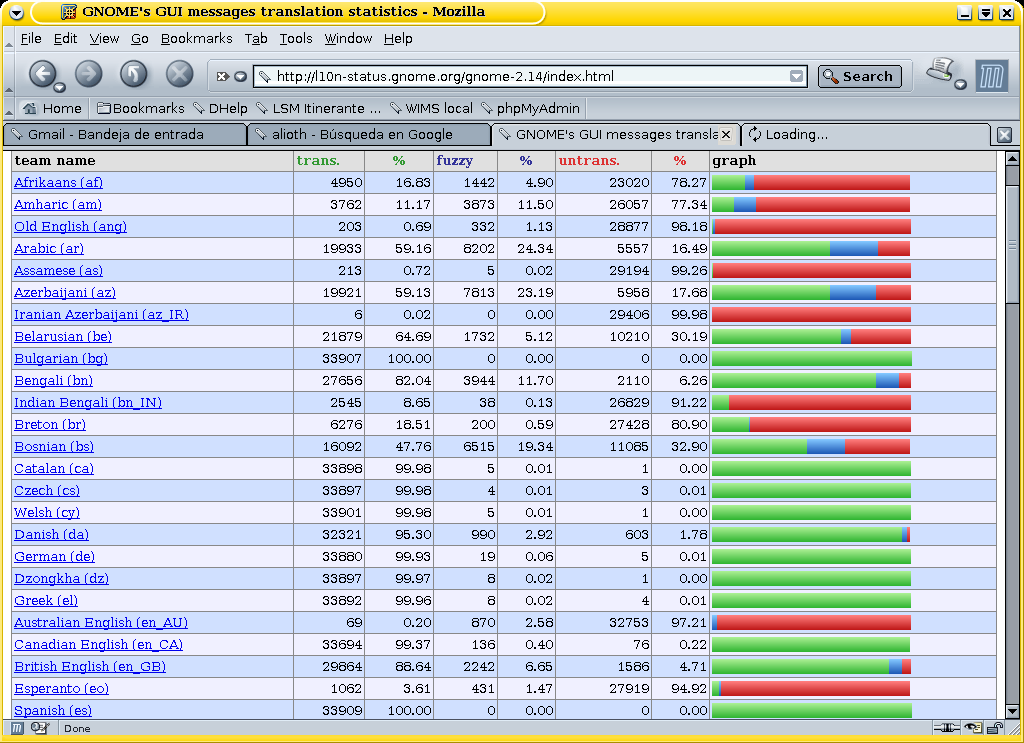
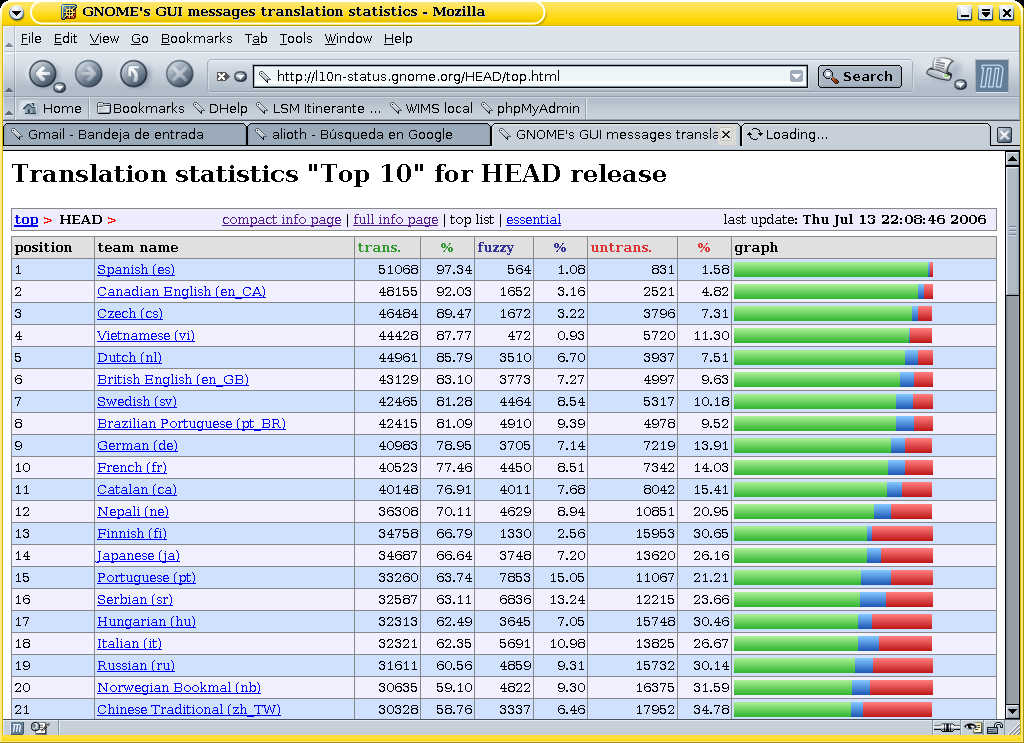
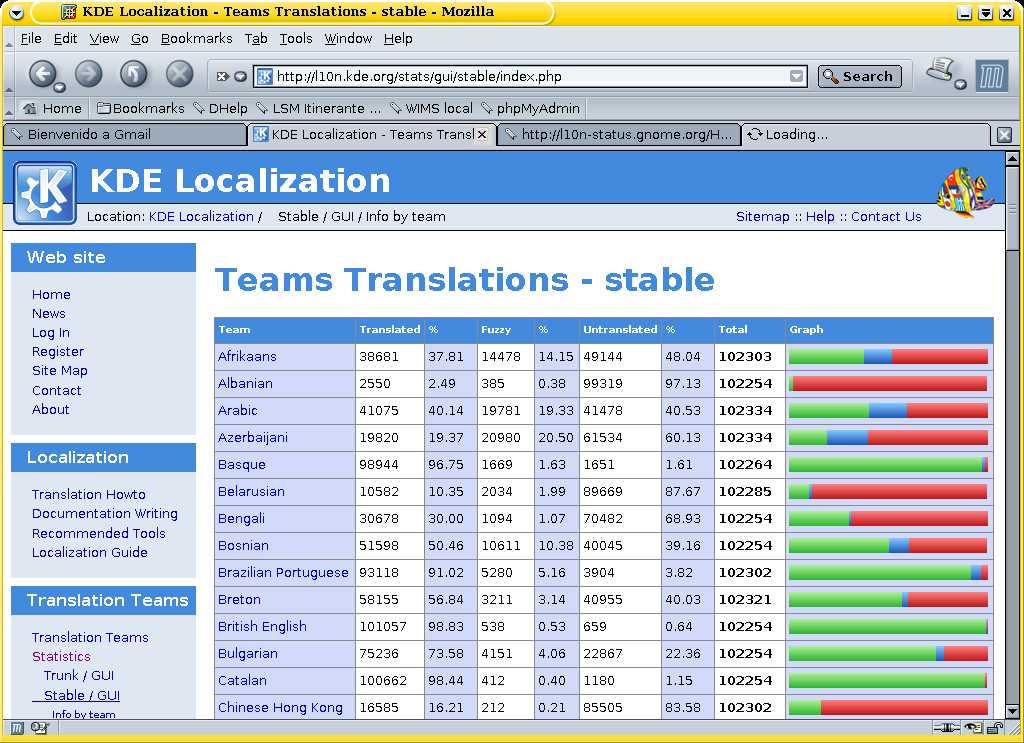
Segundo ejemplo: las estadísticas del grupo de traducción del proyecto GNOME (figura 2). ¡El equipo español había traducido el 100% de los 33.909 mensajes de la versión 2.14, la que probablemente esté presente en nuestros ordenadores! ¡Y en julio de 2006 el equipo va en primer lugar (figura 3) en el top ten de los equipos en la tarea de traducir la nueva versión (la 2.16)! Tercer ejemplo: estadísticas de los equipos del proyecto KDE, otro trabajo ímprobo (figura 4).
Y la reflexión: ¿de verdad creen ustedes que al software comercial le interesa la traducción a idiomas tan minoritarios como el esperanto, el azerbayán o la lengua de las Islas Feroe? ¿o que les compensa tener al día sus traducciones al vasco o al bretón? ¿que cada Service Pack pasa por sus equipos de traducción?
Quisiera que estas cifras, que al menos a mí me resultan asombrosas en equipos de voluntarios, sirvan para que cambie nuestra reacción cuando encontremos un error de traducción o que alguna cadena del programa que estamos usando está en inglés. Lo más probable es que se trate de un error que se corrigió hace año y medio y la corrección nos esté esperando en la nueva versión de la distribución; pero si no es así, ¿por qué no les enviamos un correo con el error y su corrección?
En nuestros artículos sobre la multilingualización (al final me gustará la palabra) de los números 4 y 5 de Linux Magazine ya tuvimos que tratar estos conceptos básicos para comprender cómo se puede adaptar un sistema a distintas lenguas. Es el momento de refrescar los conceptos.
La internacionalización (abreviada i18n, por el número de letras entre la i y la n) es la adaptación que los desarrolladores tienen que hacerle a los programas para que sea posible traducirlos y adaptarlos a distintos idiomas (la adaptación va más allá de la mera traducción: de un idioma a otro cambian el orden alfabético, el signo de la moneda o el separador de decimales...). La localización (l10n) es lo que hace el traductor, gracias al trabajo previo de i18n.
Entonces este artículo que ahora tenemos entre manos trata del estado de la localización al castellano del software libre, de cómo se realiza y de cómo se puede echar una mano (y por añadidura de la localización a cualquier otro idioma, por supuesto). Pues bien, empecemos diciendo que la localización del software libre es una labor de equipo, que sólo muy raramente es realizada por una sola persona. En primer lugar el programador debe preparar su código, y es él el que genera (pronto lo veremos) los ficheros que deberán ser traducidos. Pero además los traductores suelen agruparse en equipos: uno traduce, otro revisa, alguien coordina el reparto de trabajo y anima... entonces se envía la traducción al programador y quizás también a los mantenedores de los paquetes; y el proceso no acaba aquí, porque es normal que las aplicaciones tengan nuevas versiones, habrá que actualizar los ficheros que se van a traducir, realizar nuevas traducciones comprobando que la terminología es coherente, lo que añade una capa de control de calidad...
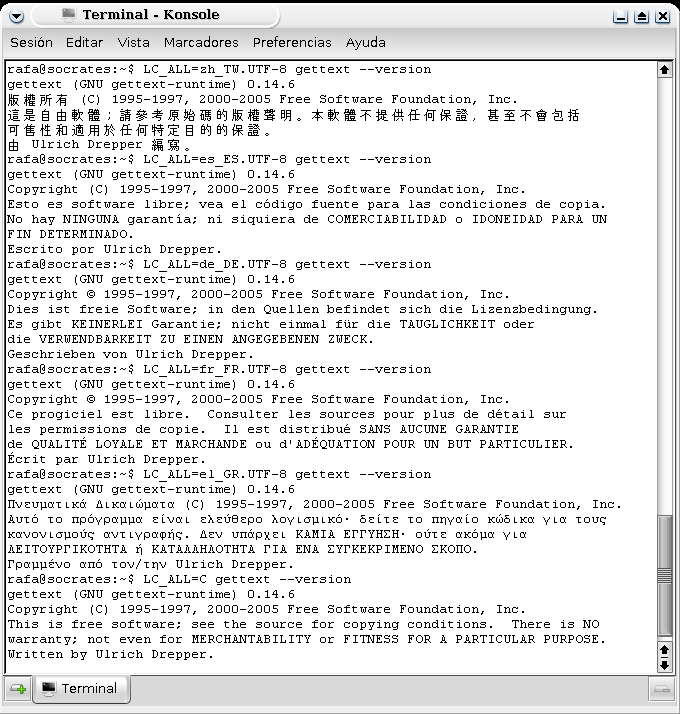
Pero estábamos explicando la localización. ¿Cómo sabe el sistema en qué idioma queremos los mensajes? Mediante unas variables de entorno, los LOCALES, cadenas como LANG=es_ES@euro o LC_ALL=zh_TW.UTF-8 (man(1) locale). Estas variables pueden fijarse en ficheros de configuración únicos para todo el sistema (caso de que por ejemplo no queramos la localización más que en castellano), o pueden ser libremente modificados por el usuario (supongamos un ordenador de un centro bilingüe en la que se desee que en determinadas clases la interfaz esté en inglés o alemán). La flexibilidad es tal que es posible modificar la localización programa por programa sencillamente anteponiéndole el LOCALE deseado. Como prueba, la figura 5, la información de la versión del programa gettext bajo distintos LOCALES. Parece magia, ¿verdad? ¿Cómo funciona esta magia?
Cuando instalamos un paquete cualquiera no sólo instalamos su ejecutable, instalamos además las cadenas de texto de todos los idiomas a los que ha sido traducido[2]. Estas cadenas cuelgan todas del directorio /usr/share/locale. Por aclarar la cuestión, en el ordenador en el que escribo hay ahora mismo 932 archivos en /usr/share/locale/es/LC_MESSAGES, todos con la extensión .mo.
MO viene de Machine Object, y es el formato binario en el que almacenan en el ordenador los mensajes. Estos ficheros .mo se generan a partir de unos archivos fuente PO (de Portable Object), que son con los que trabajamos los traductores.
Amigo futuro traductor libre, tenemos que presentar aún un paso intermedio: antes que los ficheros PO existen las plantillas PO (ficheros POT, con T de template). Un fichero POT inicial es el esqueleto, común a todos los idiomas, al que el traductor de cada lengua irá añadiendo sus traducciones. ¿Cómo y quién crea un fichero POT? El autor del programa. Mediante la herramienta xgettext del paquete gettext (ver cuadro 1 para la historia de gettext) aplicada a un archivo fuente de código que previamente ha sido internacionalizado. Esto es más fácil de comprender que de explicar, y los detalles no nos incumben a los traductores. Por poner un ejemplo el código fuente de drgeo tiene la siguiente línea
printf (_ ("\nMiss a filename to evaluate in --evaluate\n\n"));
Para los que no sabemos programar: printf es la función en lenguaje C que sirve para imprimir (en pantalla) mensajes; ahora nos encontramos con una modificación: ``(_ ... )'' es la magia que le indica a gettext que ese es un mensaje listo para ser traducido. Xgettext se va a encargar de reunir estos mensajes (msgid) y de ir anotando en qué línea aparecen, y va a crear el fichero de texto POT inicial.
El primer traductor de drgeo se encontró al recibir el fichero POT con el siguiente fragmento correspondiente a la línea de código de arriba:
#: drgenius_main.cc:172
#, c-format
msgid ""
"\n"
"Miss a filename to evaluate in --evaluate\n"
"\n"
msgstr ""
¿Qué hay en este fragmento? La referencia a la línea del fichero fuente donde aparece la cadena de texto, la indicación de que incluye código en C («\n» es la instrucción en C de nueva línea), y msgid recoge el texto que deberá traducirse. Ahora, y sólo ahora, comienza la tarea del traductor.
Un fichero PO es esencialmente una cabecera, una lista de mensaje originales y su traducción, más alguna información de contexto y comentarios.
Empecemos por la cabecera. Esta es la del fichero que estamos estudiando, la traducción al castellano de drgeo realizada por el equipo de traductores de GNOME[3]
# translation of drgeo.HEAD.es.po to Spanish # Copyright © 1998-2006 Free Software Foundation, Inc. # This file is distributed under the same license as the drgeo package. # Miguel de Icaza,computo,622-4680 <miguel@metropolis.nuclecu.unam.mx>, 1998. # Pablo Saratxaga <pablo@mandrakesoft.com>, 1999,2000. # Francisco Javier F. Serrador <serrador@arrakis.es>, 2003. # Adrian Soto <adrianmatematico@yahoo.com.mx>, 2003,2004. # Francisco Javier F. Serrador <serrador@cvs.gnome.org>, 2004. # Rodrigo Marcos Fombellida <rmarcos@cvs.gnome.org>, 2005,2006. msgid "" msgstr "" "Project-Id-Version: drgeo.HEAD.es\n" "Report-Msgid-Bugs-To: \n" "POT-Creation-Date: 2006-07-14 18:19+0200\n" "PO-Revision-Date: 2006-03-11 23:47+0100\n" "Last-Translator: Rodrigo Marcos Fombellida <rmarcos@cvs.gnome.org>\n" "Language-Team: Spanish <traductores@es.gnome.es>\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "X-Generator: KBabel 1.10.2\n" "Plural-Forms: nplurals=2; plural=(n != 1);\n"
Vemos el copyright, el listado de traductores que han trabajado a lo largo del tiempo en el fichero, la fecha de creación de la plantilla y de traducción (¡anterior! porque no se ha revisado o porque no ha habido cambios), y cierta información sobre el archivo (codificación, herramienta con la que se ha creado...). Antes de ver cómo se trabaja en la práctica comentaremos la última línea. ¿Qué es eso de las formas de plural? Es la última novedad del formato PO (vea de nuevo el cuadro 1). Un ejemplo nos aclarará la cuestión:
#: src/msgcmp.c:338 src/po-lex.c:699 #, c-format msgid "found %d fatal error" msgid_plural "found %d fatal errors" msgstr[0] "s'ha trobat %d error fatal" msgstr[1] "s'han trobat %d errors fatals"
Es común que a la hora de programar o traducir no sepamos si la salida calculada (la determinación de una variable) va a ser singular o plural (¿se producirá «un error» o «varios errores»?); además el número de formas del número varía según el idioma, desde nuestras dos formas hasta un número sorprendente. Esta nueva instrucción intenta dar solución al problema. Ahora puede informarse del número de formas singulares y plurales de la lengua destino (algunas lenguas no tienen forma de plural, otras tienen hasta cinco) y de las reglas para elegir las formas (por ejemplo el inglés o el castellano usan el singular para 1 elemento, el plural para el resto, pero hay lenguas que usan la forma singular para los números que acaban en 1: 21, 31...)[4].
En polaco la línea de la cabecera sería
"Plural-Forms: nplurals=3; \
plural=n==1 ? 0 : \
n%10>=2 && n%10<=4 && (n%100<10 || n%100>=20) ? 1 : 2;\n"
Y la traducción
msgid "1 file" msgid_plural "%count files" msgstr[0] "1 plik" msgstr[1] "%count pliki" msgstr[2] "%count plików"
A la cabecera le siguen las entradas. Cada una de las entradas de un fichero PO tiene la siguiente estructura (información procedente del manual de gettext)
ESPACIO EN BLANCO # COMENTARIOS DEL / DE LOS TRADUCTORES #. COMENTARIOS AUTOMÁTICOS #: REFERENCIA(S)DEL MENSAJE... #, MARCAS (traducción dudosa, c-format...) msgid CADENA EN IDIOMA ORIGINAL msgstr CADENA TRADUCIDA
La labor del traductor al francés consistió en rellenar en el fichero que había recibido
01 #: drgenius_main.cc:172
#, c-format
msgid ""
"\n"
"Miss a filename to evaluate in --evaluate\n"
"\n"
msgstr ""
"\n"
"Il manque un nom de fichier dans --evaluate\n"
"\n"
Esto podía haberlo hecho con cualquier editor de textos. Pero los traductores disponemos de herramientas especializadas que simplifican enormemente nuestro trabajo. Es el momento de conocerlas. Pero antes vamos a repasar el ciclo de trabajo del que hablábamos. ¿Qué ocurre si el desarrollador crea una nueva versión, si el programa pasa de la versión 1.0 a la 1.1? ¿Tenemos que retraducirlo todo desde cero? ¡Vaya herramientas tendríamos si fuera así! Es el momento de conocer msgmerge.
msgmerge Traduccion_Vieja.po Nueva_Version.pot > Nuevo_Fichero.po
El programa msgmerge, por supuesto que una más del conjunto de herramientas gettext, nos va a permitir reutilizar las traducciones de las cadenas de texto ya traducidas. Con una particularidad: si la cadena no es exactamente la misma entre una versión y la otra (el autor ha podido hacer cualquier pequeña modificación), va a marcar la traducción como dudosa (fuzzy).
#: web/template/editaccount_main.tpl:31 #, fuzzy msgid "New password (again)" msgstr "Contraseña nueva" # jr: aceptado # jorge: en este caso yo pondría "información", en vez de "datos". # It is more suitable to the context. #: web/template/editaccount_top.tpl:2 msgid "You may modify your account data here." msgstr "Puede modificar la información de su cuenta aquí."
En este ejemplo real podemos ver dos de los elementos que hemos comentado. En la primera entrada vemos que el autor ha añadido a una cadena ``New password'' la palabra ``(again)''; msgmerge encuentra la cadena similar, pero marca la traducción como dudosa, para que el traductor sepa que debe revisarla. Traducirá ``Contraseña nueva (repetir)'' y borrará entonces la marca fuzzy.
La segunda entrada es un ejemplo de colaboración entre traductores que debe leerse de abajo-arriba: el primero había traducido ``data'' por ``datos'' y el segundo sugiere que por el contexto ``información'' sería una traducción más apropiada. Aunque la decisión última corresponde al traductor y no al revisor, aquel acepta la sugerencia.
Hemos hablado de reutilizar traducciones ya realizadas. Y hemos hablado de equipos de traductores, que traducen un número alto de ficheros. Es muy probable que haya expresiones («Guardar fichero», «¿Confirma que desea usted borrar este archivo?»...) que se repitan una y otra vez. ¿No sería útil reunir las expresiones traducidas en un gran fichero de texto, que nos facilite la traducción cuando la expresión vuelva a aparecer y nos sugiera una traducción aproximada si se da una equivalencia? Esta es la idea que hay detrás de los llamados compendia, compendios de traducciones: grandes catálogos de mensajes traducidos. Se generan con una nueva utilidad, msgcat
msgcat -o compendium.po Fichero1.po Fichero2.po
Podríamos seguir examinando utilidades de la línea de órdenes que examinan la corrección ortográfica de un fichero PO o su corrección sintáctica... pero creo que hemos abusado ya de la paciencia de nuestro futuro traductor habituado a interfaces gráficas. En un equipo bien organizado es posible que nunca se vea obligado a utilizarlas porque existen editores PO especializados.
Existen, decíamos, varios editores de ficheros PO. Históricamente el primero es el modo po de emacs (se encuentra en el paquete gettext-el), y aún el manual de gettext hace continuas referencias a él. Si embargo este editor se ha quedado atrás en el tema de los catálogos de mensajes[5].
Gtranslator fue durante bastante tiempo la alternativa GNOME a la herramienta de KDE que veremos más adelante. Sin embargo es un proyecto que se quedó desfasado: aspectos tan importantes como las formas de plural simplemente no funcionan.
Otra opción es poedit, útil si se piensa trabajar en Windows. Sin embargo las lenguas no latinas no acaban de funcionar.
La opción elegida por la gran mayoría de los traductores actuales es kbabel, de KDE (de hecho sólo conozco a un traductor que use poedit, y a algunos viejos hackers que siguen con el modo po). Dos aportaciones destacan en kbabel: el potente y flexible gestor de catálogos de mensajes y la posibilidad de utilizar diccionarios, sean archivos PO auxiliares (personalmente uso las traducciones francesas para tener una referencia de cómo se ha solucionado algún problema de traducción en otro equipo) sean Compendios PO[6].
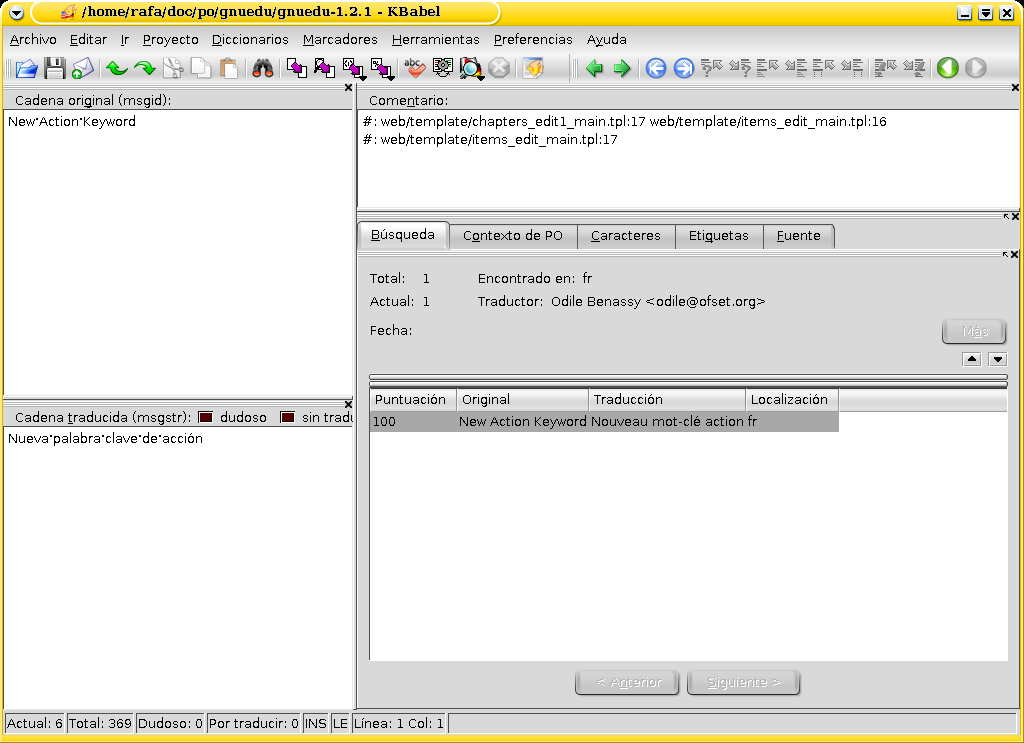
En la figura 6 tenemos un ejemplo de kbabel en uso. Ahora podemos respirar: menúes, iconos, todo lo que se necesita para vivir... Vale vale, sin ironías. Por lo pronto el espacio de trabajo se divide en varios subespacios bien delimitados. El traductor ya no corre el peligro de modificar por error el texto original en lugar de la msgstr: sólo puede escribir en el espacio que corresponde a sus traducciones, presentadas una a una. Vemos que el espacio para referencias y comentarios se ha separado. Y lo que es más importante, vemos el uso que hemos ido citando de los compendios y de los ficheros PO auxiliares: en este caso la interfaz nos presenta también la traducción al francés de la misma cadena, lo que es muy práctico a la hora de tomar decisiones de traducción en caso de duda (y más aún si sabemos que la autora del programa es francesa y que su traducción es posiblemente más correcta que el original inglés).
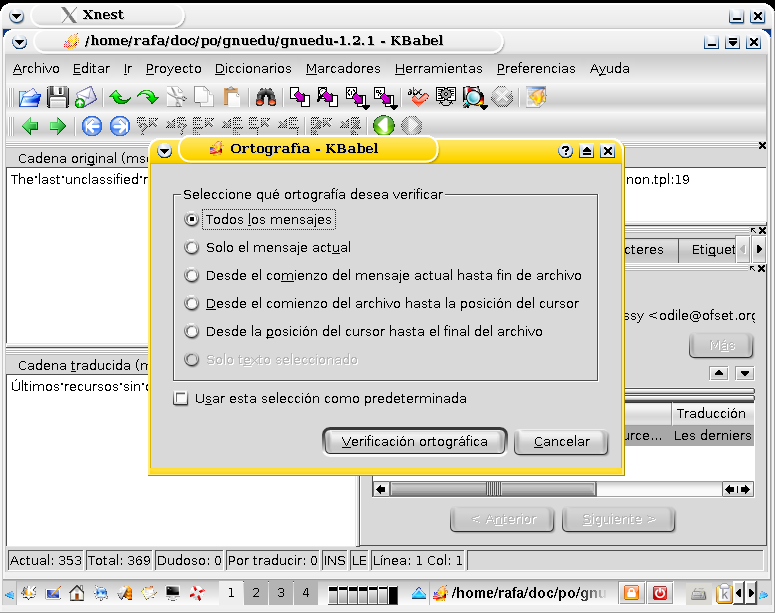
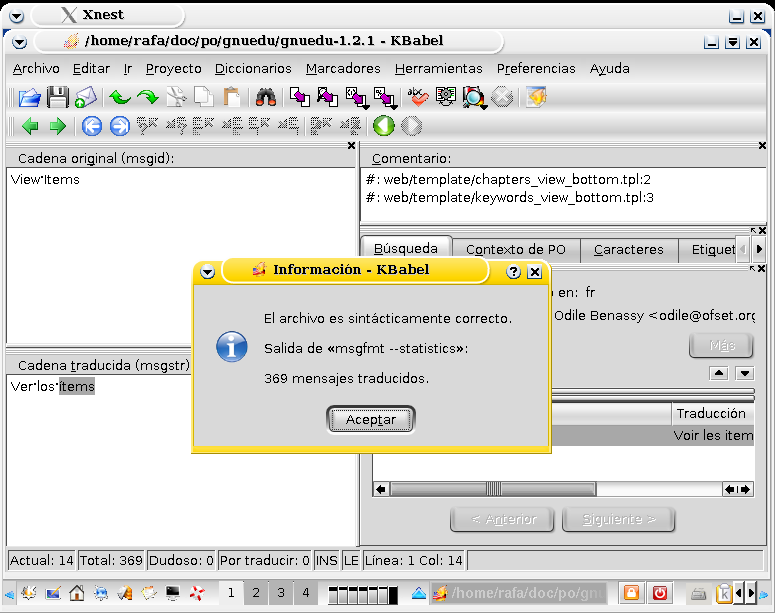
También es importante la línea de estado de la parte inferior de la interfaz: nos informa del número de mensajes del programa, pero también de los mensajes que todavía están marcados con dudosos y de los que nos faltan por traducir. Dos herramientas son importantes y no debemos dejar de destacarlas: por un lado es posible (figura 7) realizar una revisión ortográfica, tan necesaria a veces, de todos los mensajes traducidos. Por otro lado debemos siempre validar la correción sintáctica de nuestro fichero antes de decidirnos a dar la traducción por terminada; eso se realiza (figura 8) desde el menú Herramientas -> validación -> comprobación de sintaxis.
¿Cómo se genera el fichero MO? Permitan por un segundo que vuelva a la línea de órdenes.
msgfmt -v -o Fichero.mo Fichero_es.po
¿Fácil, verdad? Y si ponemos en fichero MO en /usr/share/locale/es/LC_MESSAGES ya tendremos en uso la nueva traducción. Pero queremos que la pueda utilizar todo el mundo, no sólo nosotros ¿verdad?
Hemos hablado de los ficheros PO; será el momento de resumir sus ventajas pero también de señalar los defectos de esta tecnología. Nos falta también hablar de las nuevas herramientas disponibles, de las alternativas al formato... Por lo demás hemos insistido en que la traducción es cosa de equipos y de que tenemos la oportunidad de colaborar con estos equipos, nos falta conocerlos un poquito más de cerca. Quedamos citados para la próxima entrega.
| Historia de gettext |
|
Todo empezó en julio de 1994, cuando Patrick D'Cruze tuvo la iniciativa de internacionalizar la versión 3.9.2 de GNU fileutils. Se puso en contacto con Jim Meyering, el responsable del paquete, para ponerse de acuerdo sobre cómo incorporar sus cambios a una versión oficial. Las primeras soluciones eran bastante insatisfactorias, hasta que Ulrich Drepper, responsable de la biblioteca C del proyecto GNU (GNU libc), se implicó en el proyecto. Partiendo de cero escribió lo que primeramente se conoció como msgutils, después nlsutils (a partir de «Native Language Support»), y finalmente gettext; fue aceptado oficialmente por Richard Stallman hacia mayo de 1995[7]. En resumen la primera versión oficial del paquete gettext, la 0.7, es de julio de 1995. Pero la historia de gettext va insaparablemente unida a la del Proyecto de Traducción Libre. Simultáneamente al trabajo de Drepper, François Pinard había adaptado media docena de paquetes GNU a gettext, proporcionando así un entorno de usuario efectivo para probar y afinar las nuevas herramientas. También se hizo cargo de la responsabilidad de organizar y coordinar el Proyecto de Traducción. Tras casi un año de intercambio de mensajes de correo informales entre personas de muchos países, en mayo de 1995 empezaron a existir los primeros equipos de traductores, mediante la creación de veinte listas de correo para veinte idiomas nativos. La idea de François Pinard era crear un sistema de ayuda a los programadores que crearan Software Libre, de manera que les resultara fácil encontrar traductores para sus programas (presentaremos este servicio y los distintos equipos de traductores en la segunda parte del artículo). La historia de gettext continúa. En 1997, Ulrich Drepper liberó la GNU libc 2.0, que incluía las funciones `gettext', `textdomain' and `bindtextdomain'. En el año 2000 el mismo Drepper hizo la última modificación de gran trascendencia: añadió el manejo de las formas plurales (mediante la función `ngettext') a GNU libc. Después, en 2001, publicó la GNU libc 2.2.x, la primera biblioteca C libre plenamente internacionalizada. Desde el año 2000 el responsable de GNU gettext es Bruno Haible. Haible ha añadido el manejo de las formas plurales a las herramientas también, ha incorporado los LOCALES UTF-8 y chino, japonés y coreano (conocidos como CJK), y ha escrito nuevas herramientas para trabajar con los ficheros PO. |
[1] Sobre el instalador de Debian, http://d-i.alioth.debian.org/manual/po_stats/ y http://d-i.alioth.debian.org/l10n-stats/. Sobre GNOME http://developer.gnome.org/projects/gtp/. Para KDE, http://l10n.kde.org/stats.php.
[2] Esto es verdad si se han generado los LOCALES (dpkg-reconfigure locales; para ver los que tiene instalados locale -a), pero también es verdad que si en nuestro sistema está instalada la aplicación localepurge se borrarán los mensajes de todos los idiomas que no hayamos seleccionado y además probablemente los ficheros man de ayuda (se puede reconfigurar con dpkg-reconfigure localepurge). Esto sirve para ganar espacio de disco, a costa de perder tiempo (borramos lo que ya estaba instalado) e idiomas (¿francés?, ¿catalán?) que quizás queramos poder utilizar en algún momento.
[3] Hemos buscado la versión más reciente en http://l10n-status.gnome.org/HEAD/PO/drgeo.HEAD.es.po.
[4] Información encontrada en la sección 10.2.5, «Additional functions for plural forms», del manual de gettext. La problemática que ha dado pie a estas funciones adicionales se había planteado ya en 1999 en el artículo «Localization and Perl: gettext breaks, Maketext fixes», de Sean M. Burke y Jordan Lachler, publicado en el número 13 del The Perl Journal, y disponible en nuestros ordenadores (paquete perl-doc) como salida de la orden man 3perl Locale::Maketext::TPJ13.
Hay problemas similares al de las formas de plural que no se han tratado todavía, como el del caso o el del género; recuerdo los problemas con los que me he encontrado en expresiones como «¿desea abrir un ... hoja de ejercicios?». Aunque cuando se han discutido en la lista Translation-i18n se ha reconocido la dificultad de una posible solución y se han remitido a una necesaria «educación del programador para que use oraciones completas» (palabras de Bruno Haible).
[5] Puede ampliarse la información sobre los editores PO en «Debian Installer Internationalization and Localization Guide», escrita por el equipo de desarrollo del Instalador de Debian: Petter Reinholdtsen, Dennis Stampfer, Christian Perrier (http://d-i.alioth.debian.org/i18n-doc/apes01.html) y en el estudio de 2003 http://es.tldp.org/Articulos/0000otras/doc-traduccion-libre/doc-traduccion-libre/.
[6] La página web de kbabel es http://kbabel.kde.org/ y tenemos un listado de características en http://kbabel.kde.org/features.php. El autor original es Matthias Kiefer y actualmente lo mantiene Stanislav Visnovsky.
[7] Este sección es un resumen de la sección 14.1 «History of GNU gettext» del fichero info de gettext. Probablemente tenga usted el fichero completo instalado en su ordenador. Si no es así puede leer el manual de gettext en formato html en http://www.iro.umontreal.ca/translation/HTML/gettext.html (en inglés).