La dura realidad de las dificultades anteriores nos enseña la necesidad de interfaces unificadas de comunicación entre los motores de síntesis de bajo nivel y los programas de usuario. Vamos en la presente entrega a evaluar speech-dispatcher y kttsd. Por Juan Rafael Fernández García.
| Historial de versiones | ||
|---|---|---|
| Revisión 0.1 | 2007-06-04 | jrf |
| Primera versión CC 2.0 del artículo de Linux Magazine. | ||
Está usted leyendo Presente imperfecto, futuro brillante, segundo de una serie de cuatro artículos sobre la síntesis de voz y la accesibilidad en 2007 publicado por primera vez en el número 25 de la revista Linux Magazine, de marzo de 2007 (pero escrito en enero de 2007). La versión pdf del artículo puede descargarse en el enlace http://www.linux-magazine.es/issue/25/.
La versión «canónica» del artículo, la única mantenida por el autor, se encuentra en http://people.ofset.org/jrfernandez/edu/n-c/orca_2/index.html. Está publicada por contrato con la editorial bajo licencia Creative Commons Reconocimiento-NoComercial-CompartirIgual 2.0 (-sa-by-nc 2.0).
Índice de la segunda parte
I. Una perspectiva necesaria
II. Speech-dispatcher
III. Síntesis en KDE3
IV. El futuro de KDE
V. Y en el próximo número...
Cuadro 1: El problema del sonido
Imágenes
Notas
Lectores de pantalla para consola
(Primera parte de la serie)
Síntesis de voz en gnome
(Tercera parte de la serie)
Llega el juez de la Orca
(Cuarta y última entrega de la serie)
Recordemos nuestro reto: síntesis de voz de calidad, en los idiomas que se enseñan en nuestros centros. Nos quedamos al final de la entrega anterior preguntándonos cómo salir del ghetto de una solución segregada: nuestra propuesta debe ser generalizable e integradora, lo que conlleva la presencia en distribuciones generalistas, por un lado, y desde el punto de vista simétrico la posibilidad de utilizar las mismas aplicaciones que el resto de los alumnos.
Quizás no justificamos entonces suficientemente nuestra preferencia por la síntesis por software sobre el uso de dispositivos hardware. Por un lado se explica por nuestra apuesta convencida por soluciones generalizables (el software libre es software para todos): un motor por software es un bien intelectual, si lo distribuyo sigo siendo dueño de mi copia; en cambio un motor por hardware es un bien material, si lo presto ya no lo tengo. Pero además desde el punto de vista teórico (y, seamos realistas, no sé a partir de qué momento también en la práctica) la flexibilidad y configurabilidad que permite la síntesis mediante algoritmos y reglas no tiene comparación: voces masculinas y femeninas, más o menos agudas, que hablan en diferentes idiomas a mayor o menor velocidad, actualizables con diccionarios o nuevos formatos de síntesis...
Necesitamos un poco de perspectiva para enfocar adecuadamente el tema. Los problemas los conocemos ya, necesitamos examinar qué soluciones propone la comunidad. Y sí que existe una comunidad de desarrollo constituida en torno a la accesibilidad, con discusiones, análisis y finalidades unificados. Vamos a empezar conociendo los objetivos de la «carta de la accesibilidad» del Free Standards Group, FSG[1], de septiembre de 2003. Estos objetivos incluyen, entre otros
«Debe ser posible que cualquier usuario con necesidades educativas especiales pueda acceder a todas las interfaces de usuario presentes durante el proceso de inicio, incluidos la selección del núcleo que se va a iniciar, los modos de recuperación, la carga interactiva de dispositivos, etc.»
Sobre este primer objetivo volveremos cuando tengamos una opinión formada sobre el estado de las tecnologías de síntesis. Pero queda en pie la exigencia, que asumimos: sólo si el sistema de accesibilidad está habilitado desde que se enciende el ordenador las personas con problemas de vista lograrán la autonomía total en su trabajo con el ordenador.
«Se coordinará el desarrollo de una API estándar para los servicios TTS, que permita el uso de múltiples idiomas e incluya la posibilidad de cambiar de forma sencilla y rápida de idioma y/o voz(...) Este proyecto adoptará o desarrollará un lenguaje de marcas estandarizado para el diálogo hablado.»
Este objetivo plantea la creación de una capa intermedia entre las aplicaciones de usuario y los motores de síntesis, que unifique y simplifique la tarea del programador; exige que esta capa sea también independiente del idioma y permita la selección ágil de una lengua u otra... incluso siguiendo las instrucciones contenidas en las marcas de un texto.
Con relación al FSG, es importante también la «aclaración sobre el desarrollo de un escritorio accesible» (así se me ha ocurrido traducir Statement On Desktop Accessibility Development, de septiembre de 2005), redactada por los miembros de Gnome y KDE que participan en el grupo de trabajo de accesibilidad. ¿Qué aclaran en la aclaración? Que a pesar de que los desarrollos actuales utilizan tecnologías que tienen su origen en Gnome, el compromiso es lograr estándares de interfaz de accesibilidad independientes de un conjunto de herramientas (o toolkit) determinado. Ponen el ejemplo de que en los planes de desarrollo de KDE4 se plantea la interoperabilidad con AT-SPI, de forma que se puedan integrar las tecnologías. En este campo la guerra de escritorios terminó hace mucho tiempo.
Hablábamos de una capa intermedia entre aplicaciones finales y motores de síntesis. Como siempre, cuando se miran de cerca las cosas son más complejas, no realizan la misma tarea speech-dispatcher, kttsd o gnome-speech. La primera propuesta que examinaremos es speech-dispatcher.
Speech-dispatcher[2], de la organización Brailcom para el proyecto Free(b)soft, es la primera gran aportación de los últimos años a la síntesis de voz en GNU Linux. Hemos visto las dificultades que crea el hecho de que las aplicaciones tengan que enfrentarse a los distintos dispositivos. ¿Debe cada programa entrar en el detalle del funcionamiento de cada máquina y de cada motor de síntesis? Ese es el esfuerzo que se ha realizado en las propuestas de la primera entrega, y las limitaciones y dificultades deben ser ya evidentes.
Speech Dispatcher introduce la deseada capa intermedia que aísla la síntesis de voz de los dispositivos de bajo nivel, con el objeto de facilitar el trabajo de los desarrolladores. Se caracteriza por presentar una interfaz de programación independiente del sintetizador utilizado, y se encarga de traducir las órdenes a un lenguaje que comprenda cada dispositivo.
Desde el punto de vista de los usuarios la acción de la aplicación es más evidente aún: proporciona una interfaz unificada de configuración para la síntesis de distintos idiomas mediante el uso de diferentes motores. Aporta dos ventajas adicionales clave para nuestros objetivos: por un lado la entrada de texto debe ser en UTF-8 (una función de speech-dispatcher-festival reconvierte el formato para que sea aceptable como entrada de 8 bits para festival); además avanza en la solución de la pesadilla de los motores de sonido (ver cuadro) porque permite utilizar alsa como salida para todos los motores de síntesis ¡independientemente de si el motor ha sido compilado como una aplicación oss!
Para nuestro experimento buscábamos la síntesis libre de máxima calidad de los idiomas enseñados en nuestras escuelas (iba a escribir presentes en las escuelas, pero ese, el de las lenguas no privilegiadas, el árabe, chino o búlgaro de nuestros inmigrantes, es un esfuerzo distinto, al que volveremos quizás algún día). ¿Cómo se configura eso? Es el momento de arremangarse y ponerse manos a la obra. En el fichero /etc/speech-dispatcher/speechd.conf activamos un módulo para cada lengua[3]
AddModule "festival" "sd_festival" "festival.conf" "/var/log/speech-dispatcher/festival.log" AddModule "espeak-generic" "sd_generic" "espeak-generic.conf" "/var/log/speech-dispatcher/espeak.log" AddModule "cicero" "sd_cicero" "cicero.conf" "/var/log/speech-dispatcher/cicero.log" LanguageDefaultModule "en" "festival" LanguageDefaultModule "es" "festival" LanguageDefaultModule "fr" "cicero" LanguageDefaultModule "de" "espeak-generic" LanguageDefaultModule "it" "festival"
En /etc/speech-dispatcher/modules/festival.conf elegimos la salida alsa
FestivalAudioOutputMethod "alsa" FestivalALSADevice "default"
Para la configuración de eSpeak seguimos los consejos de Lorenzo Taylor a la lista gnome-accessibility del de 2 diciembre de 2006 respecto a los cambios necesarios en /etc/speech-dispatcher/modules/espeak-generic.conf
GenericExecuteSynth \
"echo \"$DATA\" | /usr/bin/espeak -w /tmp/espeak.wav -v $VOICE -s $RATE -a $VOLUME -p $PITCH --stdin \
&& alsaplayer -i text -q -o alsa /tmp/espeak.wav"
AddVoice "de" "MALE" "de"
GenericVolumeAdd 100
GenericVolumeMultiply 100
Para el francés, y sólo provisionalmente, en /etc/speech-dispatcher/modules/cicero.conf escribiremos
CiceroExecutable "aoss /usr/share/cicero/tts_brltty_es.py"
¿O debería ser más bien simplemente esto?
CiceroExecutable "/usr/share/cicero/tts_brltty_es.py"
Lo veremos (anticipo: ni una ni la otra). Es el momento de (¿re-?)iniciar festival y speech-dispatcher
/etc/init.d/festival start /etc/init.d/speech-dispatcher start
En /var/log/speech-dispatcher/speech-dispatcher.log debemos tener información como «Speech Dispatcher started with 3 output modules» (Speech Dispatcher iniciado con tres módulos de salida: festival, espeak y cicero). Vamos bien. ¿Cómo comprobarlo? Con la utilidad de línea de órdenes sdp-say
cat texto_utf8.txt | spd-say -l es -e
¡Escuchamos la mediocre voz española de festival! ¿Y los otros idiomas? Esa es la utilidad del parámetro -l (lengua), probemos las voces de festival: el inglés (basta con spd-say -l en "hello kid", el italiano... todo perfecto (y divertido como una imitación de acento si lanzamos el mismo texto para los distintos motores de idioma). ¿Y el alemán? Aceptable. Pero el francés nos falla: ni la opción con envoltorio alsa (el wrapper aoss) funciona, ni la salida directa oss (error «No existe el fichero o el directorio: `/dev/dsp'»). Para comprender porqué debemos leer el cuadro adjunto.
¿Solución? Si nuestra necesidad fuera exclusivamente sintetizar francés podría servirnos cicero o hacer pruebas con el módulo llia_phon-generic; pero nuestra necesidad es multilingüe y no queremos renunciar a la posibilidad de dar salida a varios sonidos simultáneamente, no tenemos porqué dejar de utilizar el ordenador para escuchar música o podcasts. Hay afortunadamente una solución manifiestamente mejor y libre sin reparos: desde la versión 1.18 eSpeak sintetiza francés. Esperemos que llegue pronto a nuestras distribuciones.
Bien, tenemos el inglés, el italiano, alemán, castellano, pronto el francés... pero desde la línea de órdenes y con un programita, spd-say, que sólo sirve para hacer pruebas (espero que nadie piense que la síntesis en GNU Linux se queda aquí). Hemos aprendido que speech-dispatcher no se utiliza directamente, que en sí misma es una capa inútil, está ahí para que una aplicación de más alto nivel, en la jerga un cliente, utilice sus servicios. ¿Cuál? Ya vimos que podía ser utilizada por herramientas para consola (emacspeak en compañía de speechd-up o speechd-el). No era eso lo que buscábamos, ¿verdad? ¿dónde están las ventanas, dónde los cuadros donde marcar opciones, nuestra sagrada interfaz gráfica de usuario? Por el momento debemos suspender la búsqueda de clientes para speech-dispatcher para examinar una tecnología de síntesis que se ha desarrollado de forma totalmente independiente.
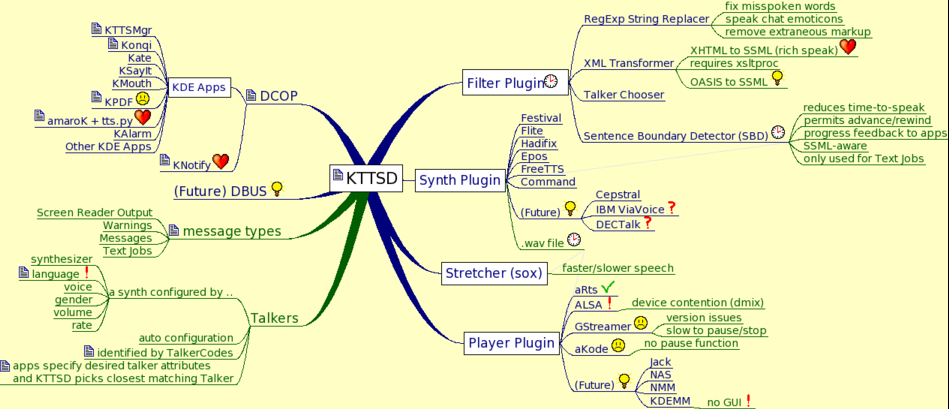
Olvidémonos de speech-dispatcher ahora y comencemos con una máquina nueva (o iniciemos nueva sesión sin speech-dispatcher ni un servidor festival y con KDE como entorno. La solución de síntesis de KDE 3.5.5 se llama KTTS[4] y se basa fundamentalmente en el trabajo del demonio kttsd. La tarea de kttsd es similar a la de speech-dispatcher en el sentido de que introduce una capa intermedia entre las interfaces de usuario y los motores de bajo nivel (la figura 1 nos muestra esquemáticamente el sistema). Normalmente se lanza automáticamente en el inicio del entorno KDE, o bien puede lanzarse de forma manual. Que está lanzado es perceptible porque instala un icono en el panel; vamos a comprobar que funciona accediendo a KTTSD directamente
# Enviamos "Hello World" a KTTSD para # que se prepare para pronunciarlo en inglés dcop kttsd KSpeech setText "Hello World" "en" # Ahora damos la orden de que lo sintetice dcop kttsd KSpeech startText 0
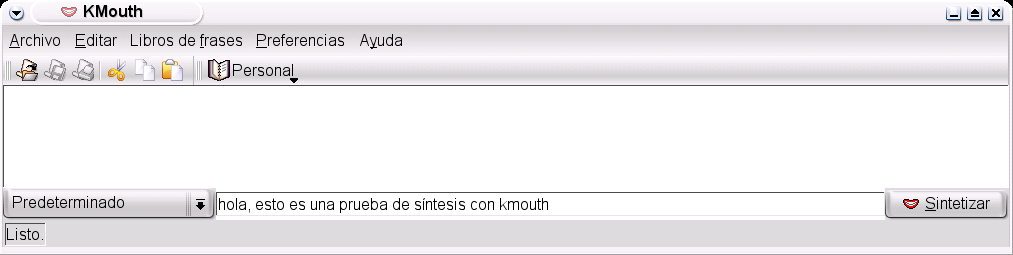
Curioso, pero poco útil salvo para ir de hacker por la vida. ¿Qué proporciona KDE que permita sintetizar el habla a un profesor o alumno de forma amigable? La forma más simple de interfaz gráfica para la síntesis de voz en KDE la constituye kmouth[5], de Gunnar Schmidt. Como nos dice el manual, «KMouth es una aplicación que hace posible que personas privadas de la facultad de hablar utilicen el ordenador para que emita las palabras por ellas». El mensaje citado en la nota nos permitirá comprender la utilidad que puede tener la aplicación: fue creado porque la madre del autor había perdido el habla.
¿Cómo funciona? Incluye una lista de oraciones que el usuario puede seleccionar para que sean sintetizadas, y le permite escribir (o copiar desde el portapapeles) las que desee hacer oir (figura 2). Para que kmouth pueda realizar la síntesis previamente ha sido necesario haber configurado KTTS.
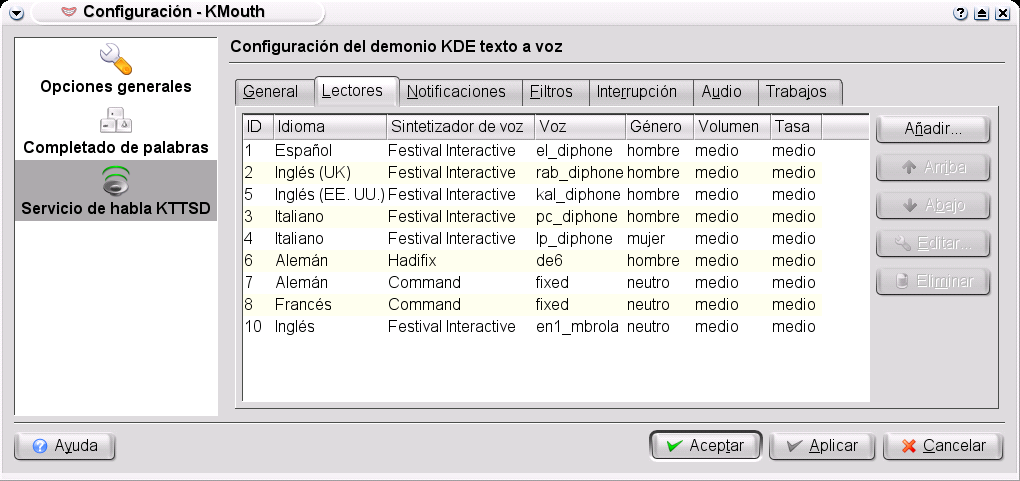
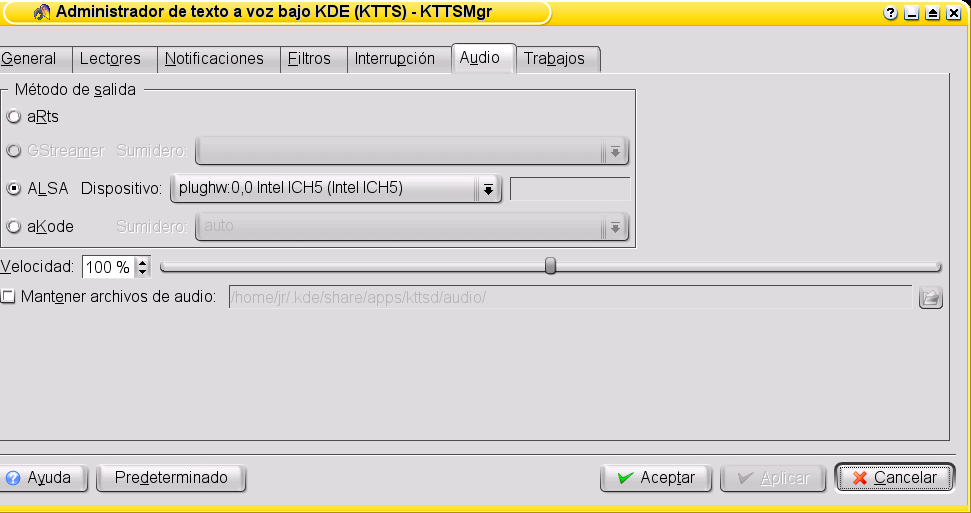
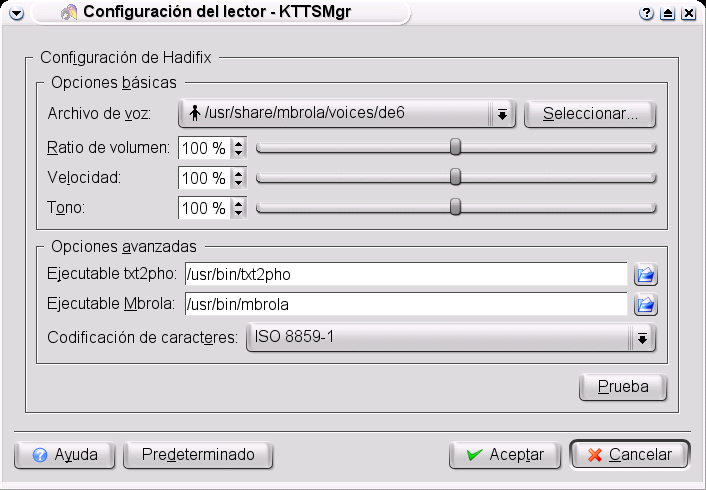
Desde el menú de configuración de KMouth (realmente lo que estamos usando en ese momento es el administrador de KTTS kttsmgr) podemos definir motores y voces (figura 3) y podemos decidir aspectos tan importantes como la salida de sonido (elegiremos alsa, figura 4). ¿Cómo se añade una nueva lengua? Fácil, la figura 5 nos muestra la cómoda interfaz (por cierto, hadifix es el nombre de la combinación de txt2pho con una voz alemana de mbrola, de6). Cuando existe una voz para festival, caso del inglés y del italiano (y del castellano si fuera satisfactoria) ya habríamos terminado. Pero sabemos que no siempre es así y tenemos que continuar nuestra investigación.
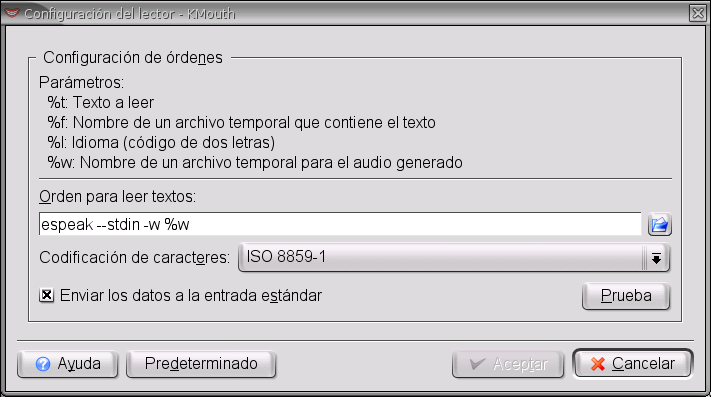
Para el alemán tenemos dos soluciones: la primera es la que acabamos de ver, que depende de software sólo parcialmente libre (vimos en la primera entrega que existen paquetes Debian preparados por Gilles Casse para Oralux). También es posible utilizar eSpeak con KTTS[6] mediante la orden
espeak --stdin -w %w
En la figura 6 podemos ver los detalles completos.
¿Y el francés? Tenemos la deficiente solución eSpeak de la versión 1.16 (se configuraría igual que para el alemán). Hay más opciones; probemos primero que funcionan los ejecutables de líneas de órdenes, cicero:
cat TextoEnFrances.txt | /usr/share/cicero/bulktalk.py
y/o
MBROLA_VOICE="/opt/voices/mbrola/fr3/fr3" /usr/bin/lliaphon_test TextoEnFrances.txt
Sería posible crear órdenes para utilizar estos ejecutables desde kmouth[7]. Pero, sinceramente, no merecen el esfuerzo; creemos que cuando se lea este artículo todos estos reparos serán historia, porque los progresos de eSpeak tras la versión 1.18 nos permitirán prescindir del uso de motores parcialmente libres para el francés. Al menos para las necesidades que cubre kmouth de síntesis de frases aisladas para un oído no nativo.
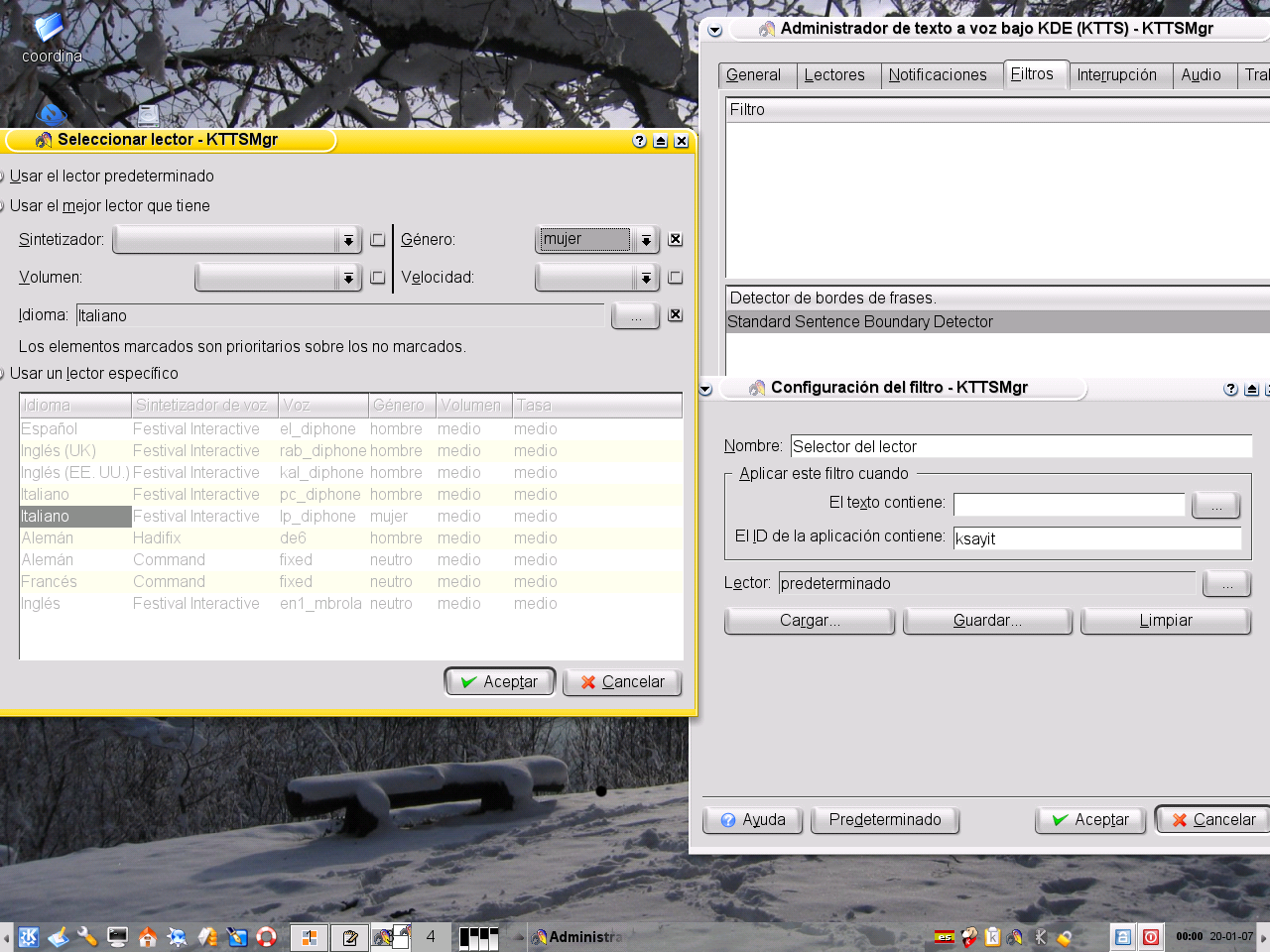
¿Cómo se cambia de idioma en kmouth? No hay un mecanismo directo como podría ser un botón o una entrada del menú; he probado a cambiar el orden de los lectores («lector» es la traducción elegida para talker, algo así como «hablador» o ¿quizás «locutor»?) desde el menú de configuración, pero la salida sigue utilizando la voz predeterminada, en mi caso la de festival en castellano. Es necesario configurar un filtro para el cambio de lector (figura 7). Nada que se aprenda en la primera semana de un curso de introducción al software libre. Y por lo demás dudo mucho de que los contenidos de /usr/share/apps/kttsd estén suficientemente internacionalizados, salvo para inglés, alemán y ¡polaco!
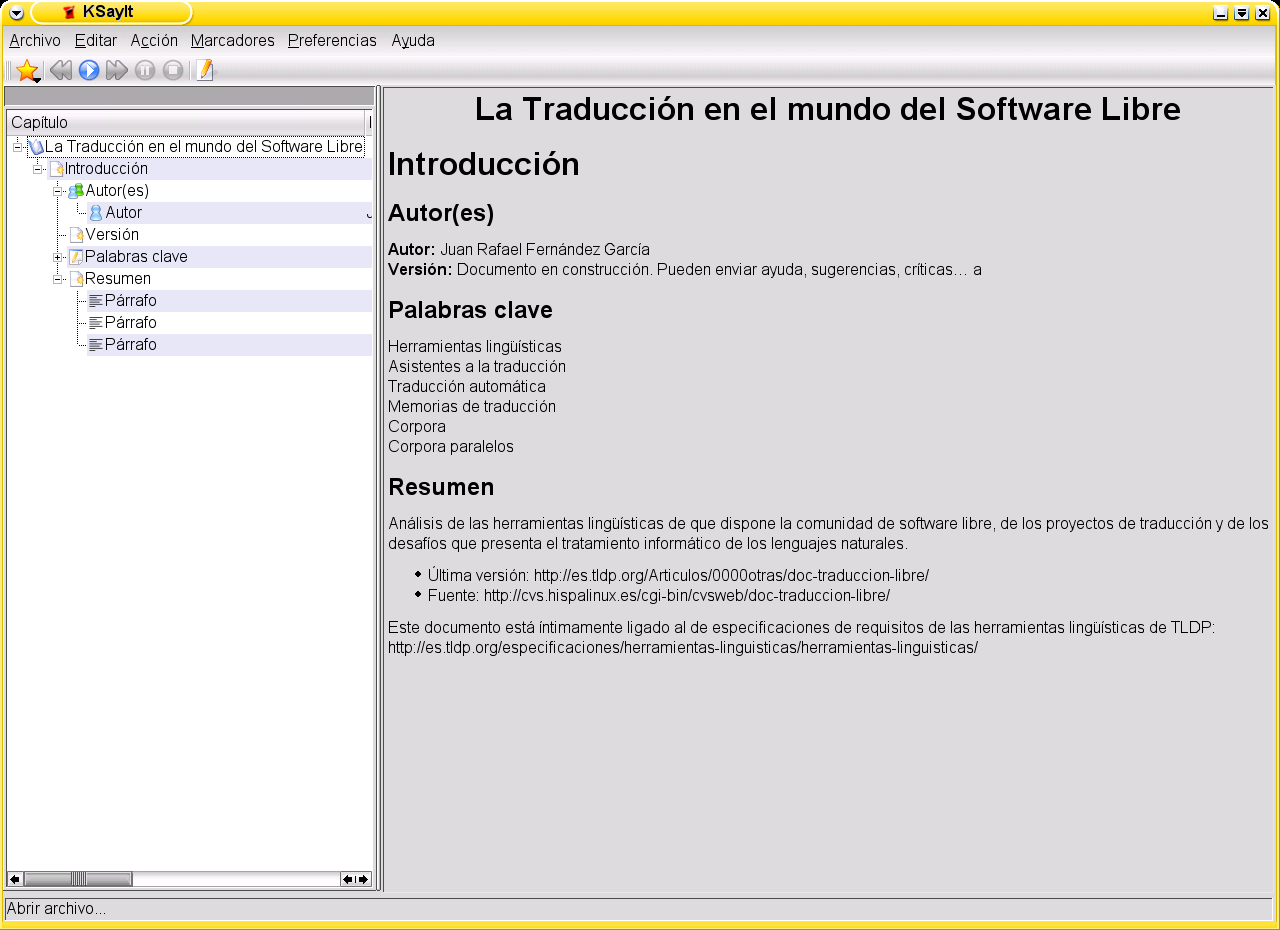
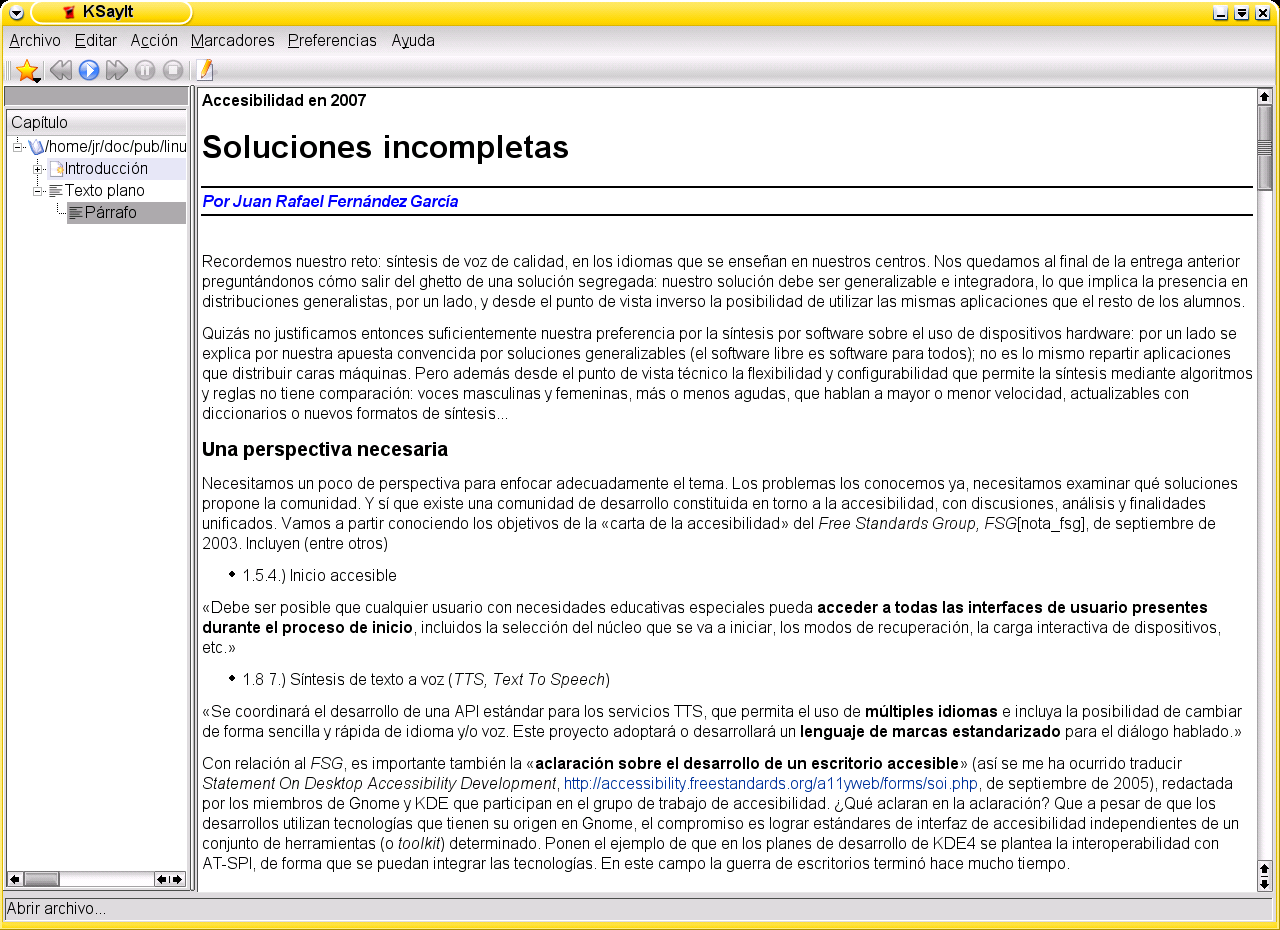
Una segunda aplicación es KSayit, de Robert Vogl. En lugar de frases aisladas permite hacer audibles textos completos. La figura 8 nos muestra cómo funciona: analiza el texto en secciones y párrafos (en este caso de trata de un documento en formato docbook) y nos permite ordenar que se sintetice el texto completo o un fragmento.
Lo cual nos lleva a tres temas en los que no vamos a poder profundizar en esta serie (todo se andará) pero que son de especial trascendencia: el marcado de textos para su síntesis, la descomposición gramatical en partes y lo que vamos a llamar el seguimiento de la posición. Muy brevemente:
He hecho varias pruebas de apertura de distintos formatos de fichero con la configuración predeterminada. Curiosamente importar el ejemplo de SSML de la página de la ayuda de KTTS, sección SSML, da un error en KSayIt: «El archivo es de tipo `speak', se esperaba `book'». Y como podemos esperar por el mensaje se importan correctamente los documentos docbook de tipo book (es el caso del documento de la captura), no los de tipo article. Tampoco abre uno de los ejemplos SABLE de la documentación de festival. Con un documento .odt la aplicación se atasca. Una vez descomprimido, si intentamos abrir el fichero content.xml reaparece el mensaje «El archivo es de tipo `office:document-content', se esperaba `book'». Con un texto plano el programa no es capaz de realizar la descomposición en párrafos. Con un texto html 4.0 la presentación visual es perfecta, pero falla estrepitosamente el análisis estructural: ¡todo el texto es un único párrafo! (figura 9).
Estoy convencido de que la solución está en una configuración correcta de los filtros de tipo Trasformador XML de KTTS (que utilizan xsltproc para pasar de una forma de xml a otra), pero no entiendo que se deje esta tarea nada trivial al usuario final. Pero esto es software libre: ¿voluntarios para encontrar soluciones de configuración, documentarlas y compartirlas?
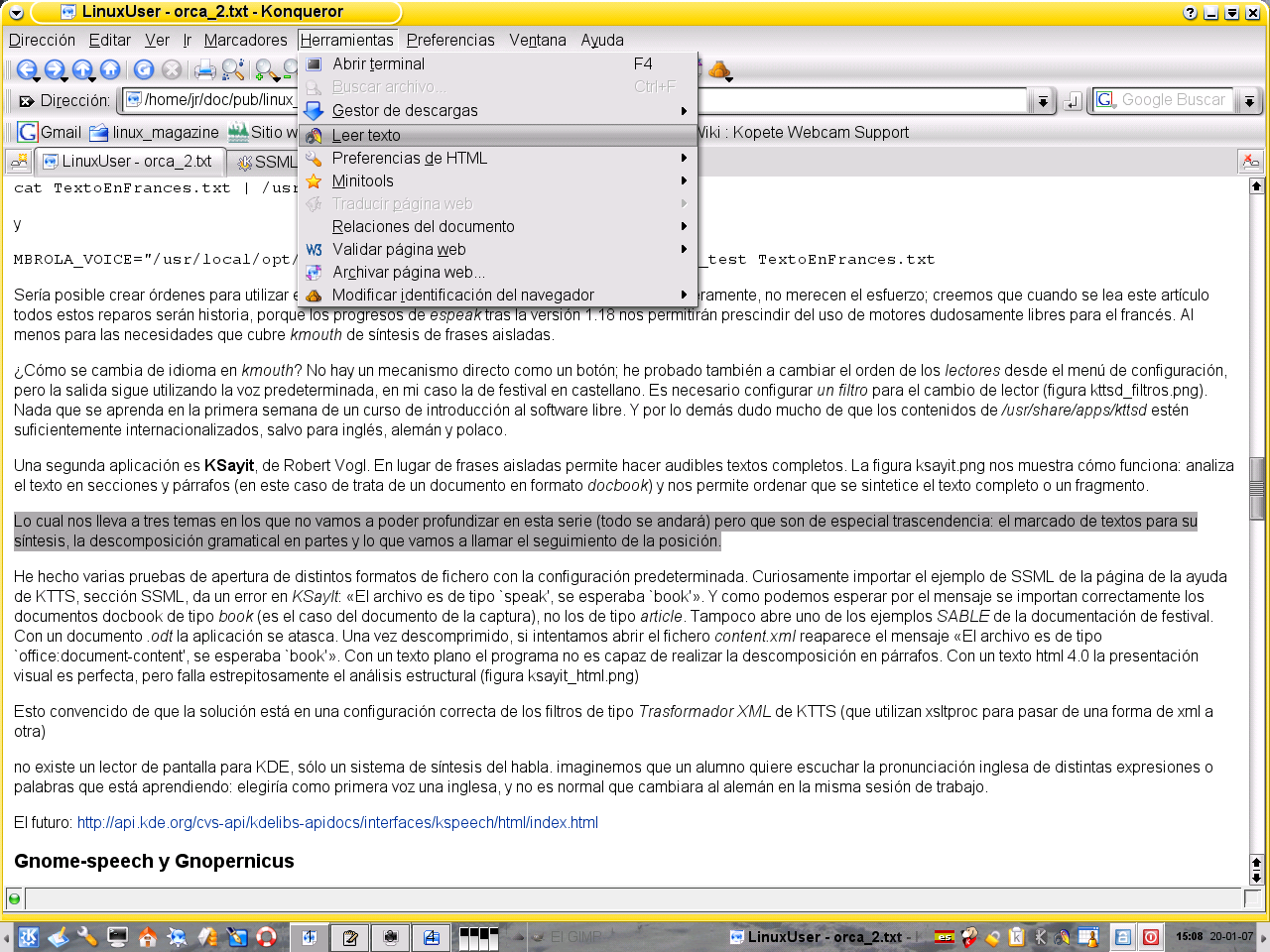
Hemos hablado de kmouth y de ksayit, pero realmente estas dos interfaces no son más que pequeños ejemplos casi anecdóticos de lo que se puede hacer con kttsd. Para sintetizar el contenido del portapapeles bastaba con pulsar con el botón derecho en el icono kttsmgr del panel y después en «Leer el contenido del portapapeles» (tan fácil que suena a perogrullada). Y, sorpresa sorpresa, desde konqueror (figura 10) o el editor kate es posible seleccionar el fragmento que desea escucharse y dar la orden de que se sintetice.
A manera de conclusión, podemos afirmar que no existe un lector de pantalla para KDE 3.5.5, sólo un sistema de síntesis del habla. Lo cual no es en absoluto inútil desde el punto de vista de la accesibilidad, pero quizás sí desde el de la tiflotecnología. El que es superlativo es el interés pedagógico de las tecnologías proporcionadas por el proyecto de accesibilidad de KDE: un alumno puede escuchar de forma autónoma, configurable y cuantas veces quiera la pronunciación inglesa de distintas expresiones o palabras que está aprendiendo, o puede hacer que el ordenador le lea un texto en francés o alemán para comprobar su nivel de comprensión oral.
No existe un lector de pantalla para KDE, decíamos. Sus documentos lo confirman: «El proyecto KTTS comenzó como un esfuerzo para proporcionar servicios de síntesis de voz para documentos extensos y en formato de libro electrónico. Los lectores de pantalla y el resto de las ayudas tecnológicas no eran la primera consideración en su diseño, al menos no inicialmente»[10]. Estas carencias de concepción no pueden dejar satisfechos a los desarrolladores.
Conocemos ya las líneas generales que la accesibilidad seguirá en KDE4 puesto que se ha publicado una «hoja de ruta». Es realmente un documento y un proyecto que no tiene desperdicio, y que merece un artículo por sí mismo (quizás el próximo año, cuando KDE4 sea una realidad en nuestros escritorios). Sólo parafrasearemos libremente una noticia clave: «El plan del proyecto KTTS en KDE4 es sustituir los plugins de kttsd de elección del sintetizador, control de velocidad, salida de audio y detector de límites de oración por speech-dispatcher». El círculo se cierra, volvemos a speech-dispatcher.
Hemos hablado con cierto detalle de realidades y de proyectos en KDE, ¿qué progresos se han producido en el entorno paralelo Gnome? Podemos adelantar que no se trata de planes y hojas de ruta, la accesibilidad en Gnome ha sufrido una revolución: adiós al rey destronado Gnopernicus, larga vida al emergente Orca... nos vemos o nos escuchamos en la siguiente entrega, ¿de acuerdo?
| El problema del sonido |
|
Se trata de una de las consecuencias más graves de la riqueza ecológica de GNU Linux. Intentaré explicarme: no es síntoma de una deficiencia, sino al contrario, del exceso de soluciones. Pero es un problema grave. ¿Cuál es el problema? Que determinadas aplicaciones tienden la bloquear el dispositivo de salida de audio, e impiden a otras aplicaciones su uso. Esto, que en circunstancias normales es sólo molesto (impediría reproducir un CD de música y escuchar los sonidos de un juego simultáneamente) desde el punto de la accesibilidad es inaceptable: si el sintetizador bloquea la salida de audio, se acabó el sonido para el resto de las aplicaciones; y si un motor para un idioma bloquea el audio, nada de cambiar de idioma o de voz. La explicación de cómo se ha ocasionado el problema es histórica. El primer sistema de sonido para GNU Linux era OSS (Open Sound System), que tenía serias limitaciones, entre otras que no permitía la mezcla de sonidos. OSS creaba dispositivos de audio en /dev, y los programas con salida para OSS escribían en estos dispositivos. Así, por ejemplo el editor de sonido audacity se esfuerza por hacerse dueño de /dev/dsp, da error si algún otro programa ha bloqueado ya el dispositivo, e impedirá que ningún otro escriba en él hasta que lo libere. Para permitir transiciones entre sonidos o que dos fuentes de audio pudieran mezclarse los distintos proyectos debieron crear demonios de audio por encima de la capa de lectura o escritura directa en los dispositivos. Ese fue el origen de esound, la solución adoptada históricamente por Gnome, o arts, de KDE. Pero estas soluciones unilaterales ocasionan nuevos problemas: las aplicaciones deben compilarse con las bibliotecas para esound o para arts; los programas escritos para OSS seguirán dando problemas, así como la convivencia en el mismo sistema de ejecutables Gnome y KDE (rhythmbox y k3b, por ejemplo), con los dos demonios compitiendo por la salida de audio. ALSA, la Advanced Linux Sound Architecture, es una solución que obligaba a parchear los núcleos 2.2 y 2.4, pero que ha sido adoptada como el sistema de sonido de Linux para los núcleos 2.6. ALSA es avanzado, como su nombre indica, altamente configurable, modular, e incluye un sistema de plugins; entre estos plugins destaca dmix (activado hoy día de forma predeterminada), que permite la mezcla de entradas en tarjetas de sonido en las que esta mexcla no se puede realizar por hardware. En los correos preparatorios de esta serie de artículos[11] Milan Zamazal enumeraba varias condiciones para que el sistema de sonido funcione sin conflictos:
# Configurar el plugin dmix
pcm.dmixer {
type dmix
ipc_key 1024
ipc_key_add_uid false # permitir que varios usuarios lo compartan
ipc_perm 0666 # permisos IPC para varios usuarios
slave {
pcm "hw:0,0" # depende de la(s) tarjeta(s)
}
}
# Utilizar dmix como dispositivo predeterminado
pcm.!default {
type plug
slave.pcm "dmixer"
}
# Redirigir todos los dispositivos OSS
# (continuar dsp1, dsp2... si hay más
# tarjetas)
pcm.dsp {
type plug
slave.pcm "dmixer"
}
pcm.dsp0 {
type plug
slave.pcm "dmixer"
}
No sé si todos estos puntos son necesarios. Sin embargo he podido comprobar que sólo tras ponerlos en práctica he logrado que funcionen los ejemplos referidos en esta serie. |
[1] «FSG» son las siglas del Free Standards Group, FSG.
El grupo de estándares libres es una organización abierta a la que se afilian
empresas e instituciones e individuos interesados en fortalecer y promover el uso de Linux
como plataforma para el desarrollo de aplicaciones. Cuenta entre sus socios a empresas de
la importancia de AMD, Computer Associates, Debian, Dell, Fujitsu, Google, HP, IBM, Intel,
MySQL, NEC, Novell, Red Flag, Red Hat, Sun Microsystems y Veritas
(información extraída de
http://www.freestandards.org/en/About).
Su actividad se divide en grupos de trabajo. El que nos interesa en este momento es el
de accesibilidad, que nace en 2003 con la carta o compromiso de la accesibilidad:
la Accessibility Workgroup Charter,
http://www.freestandards.org/en/Accessibility/Charter_v1.0. Sobre el Statement On Desktop Accessibility Development (2005), http://accessibility.freestandards.org/a11yweb/forms/soi.php.
Por cierto incluye la lista de firmantes.
[2] http://www.freebsoft.org/speechd; se aconseja
instalar junto con speech-dispatcher-festival, speechd-el (si se piensa utilizar
emacs), y sound-icons (ya vimos el concepto de iconos auditivos en la anterior entrega).
Existen paquetes Debian preparados por Milan Zamazal. Los paquetes están documentados en ficheros
de formato info: speech-dispatcher.info, festival-freebsoft-utils.info.
Importante: en el momento de escribir este artículo la versión disponible en Debian es la
0.6.1-2, inútil para el español (y para el resto de las lenguas españolas). Sencillamente
no es posible producir síntesis en castellano con esta versión (o una anterior) de
speech-dispatcher. La corrección del problema es trivial (añadir una línea
«(es spanish)» en el fichero /usr/share/festival/recode.scm), y ya se encuentra
disponible en el cvs de Free(b)soft.
[3] Recordemos que hemos descargado los módulos parcialmente libres cicero y lliaphon del sitio de Oralux (http://oralux.net). Por cierto que esto no será necesario pronto, puesto que la nueva versión de eSpeak, la 1.18 recién publicada el 13 de enero de 2007, comienza a cubrir también el francés (ver http://sourceforge.net/project/showfiles.php?group_id=159649). Las voces que funcionan en eSpeak se averiguan con espeak --voices.
[4] Para KTTS, originalmente de José Pablo Ezequiel Pupeno Fernández y actualmente mantenido por Gary Cramblitt, http://accessibility.kde.org/developer/kttsd/index.php. Puede leerse también el manual disponible en castellano en la ayuda de KDE, en la sección «Módulos del centro de control», «Texto a voz». El esquema de funcionamiento, en http://accessibility.kde.org/developer/kttsd/ktts-architecture4.png.
[5] Kmouth: http://www.schmi-dt.de/kmouth/index.en.html. Mensaje sobre el origen de kmouth, en el hilo «KSayIt and KDE Accessibility» de la lista kde-accessibility, por Olaf Jan Schmidt, el 12 de enero de 2004.
[6] Información disponible en http://accessibility.kde.org/developer/kttsd/index.php, sección «New eSpeak synthesizer».
[7] No obstante los interesados pueden leer con aprovechamiento «Synthèse vocale en français sous Linux» (del 24 de septiembre de 2006, http://kubuntu.free.fr/blog/index.php/2006/09/24/121-synthese-vocale-en-francais-sous-linux), que documenta en francés el uso de lliaphon con KTTS. O, para los anglófonos, las entradas de la bitácora de Gary Cramblitt http://phantomsdad.blogspot.com/2005/06/ktts-and-french-connection.html, http://phantomsdad.blogspot.com/2006/06/ktts-and-french-connection-ii.html (cicero) y http://phantomsdad.blogspot.com/2006/09/ktts-and-french-connection-iii.html (lliaphon).
[8] SSML en W3C: http://www.w3.org/TR/speech-synthesis/. Hay una introducción en http://www.xml.com/pub/a/2004/10/20/ssml.html. Sobre SABLE, http://www.w3.org/TR/speech-synthesis/#ref-sable. Es aconsejable la lectura de la «Guía Breve de Interacción Multimodal» (en castellano), http://www.w3c.es/Divulgacion/Guiasbreves/Multimodalidad.
[9] Gunnar Schmidt reflexionaba sobre el problema en mensaje de 10 de febrero de 2004 a la lista kde-accessibility, hilo «kttsd and KSayIt etc...». Gunnar se inclinaba porque la tarea la realizara ksayit, lo que limitaba la solución a la capacidad de descomponer sólo en párrafos que tiene la aplicación.
[10] La hoja de ruta de KDE4 http://accessibility.kde.org/developer/kttsd/roadmap.html. Sobre la interfaz kspeech, http://api.kde.org/cvs-api/kdelibs-apidocs/interfaces/kspeech/html/index.html.
[11] La parte pública de las discusiones ha quedado almacenada en http://lists.debian.org/debian-accessibility/2006/12/threads.html.
{kind=link}