En esta nueva serie de artículos vamos a intentar dar contestación a una pregunta sencilla: ¿puede GNU Linux dar respuesta a las necesidades de síntesis de voz multilingüe de nuestros centros educativos? Por Juan Rafael Fernández García.
| Historial de versiones | ||
|---|---|---|
| Revisión 0.2 | 2007-05-06 | jrf |
| Actualizadas las notas 8 y 13. | ||
| Revisión 0.1 | 2007-05-01 | jrf |
| Primera versión CC 2.0 del artículo de Linux Magazine. | ||
Está usted leyendo Lectores de pantalla para consola, primero de una serie de cuatro artículos sobre la síntesis de voz y la accesibilidad en 2007 publicado por primera vez en el número 24 de la revista Linux Magazine, de febrero de 2007 (pero escrito en diciembre de 2006). La versión pdf del artículo puede descargarse en el enlace http://www.linux-magazine.es/issue/24/.
La versión «canónica» del artículo, la única mantenida por el autor, se encuentra en http://people.ofset.org/jrfernandez/edu/n-c/orca_1/index.html. Está publicada por contrato con la editorial bajo licencia Creative Commons Reconocimiento-NoComercial-CompartirIgual 2.0 (-sa-by-nc 2.0).
Índice de la primera parte
I. Voces y motores
II. SpeakUP
III. Emacspeak, multispeech, speechd-el
IV. Conclusión parcial
V. Y en el próximo número...
Imágenes
Notas
Presente imperfecto, futuro brillante
(Segunda parte de la serie)
Síntesis de voz en gnome
(Tercera parte de la serie)
Llega el juez de la Orca
(Cuarta y última entrega de la serie)
¡Qué paradoja! Un artículo en una revista de papel, con capturas y fotos... sobre lectores de pantalla y accesibilidad. Tendrá que ser sólo una de las presentaciones posibles; irá acompañado de la versión html accesible, y en su momento será cuestión de generar una versión sonora, con capturas sonoras y no gráficas, con enlaces a los ejemplos de salida de los sintetizadores...
El acto de escritura de este artículo tiene lugar en diciembre de 2006. Han pasado casi dos años desde que en abril y mayo de 2005 escribíamos nuestro Accesibilidad en 2005, publicado en los números 6 y 7 de la revista (y consultable en la web)[1]. ¡Dos años informáticos, el equivalente a dos eras geológicas, cuatro versiones de Gnome u Ubuntu, qué digo, casi --seamos andaluzamente exagerados-- dos versiones de Debian! En un mundo, el del software libre, que evoluciona a una velocidad en aceleración, el tema de la accesibilidad no podía ser una excepción. Quizás la gran novedad sea que al fin está en primer plano, que en todos los proyectos importantes es una cuestión que ha dejado de ser secundaria; evidentemente contribuye a ello la legislación sobre accesibilidad, pero quiero creer también que se empieza a comprender que si no hay conciencia de las exigencias de la integración desde la concepción de los desarrollos, si se deja la cuestión para el final, lo más que se conseguirán son parches y apaños que poco tienen que ver con la igualdad de acceso de todos los alumnos y alumnas.
Revisando los artículos de 2005 recordamos que el objetivo era hacer una presentación de las tecnologías disponibles en aquel momento, muy poco conocidas, entonces y ahora, contra la opinión generalizada de que no existían soluciones adaptativas en GNU Linux. Ya hicimos la presentación general, y en lo general tiene vigencia aún. Es el momento de profundizar en uno de los temas tratados, el de la síntesis de voz y los lectores de pantalla, para comprender y evaluar las aplicaciones existentes.
¿Por qué centrarnos en este tema? Por tres razones: porque es imposible tratar todos los aspectos con la necesaria profundidad para que el estudio sea útil (y la panorámica de 2005, con su superficialidad, sigue ahí); porque los avances más importantes se han producido en este campo, y porque la generalización de proyectos de bilingüismo ha introducido una nueva exigencia en el sistema educativo. Intento ser convincente al exponer la idea, que no es mía, de que la síntesis de voz no es sólo importante[2] desde el punto de vista de la integración, sino también desde el aprendizaje de idiomas. Hay una utilidad evidente en que el ordenador del alumno pueda sintetizar textos en inglés, francés, alemán, catalán o italiano además de en castellano. ¡Poder escuchar un texto mientras se lee, todas las veces que se quiera! ¡O disponer al fin de un diccionario de pronunciaciones hablado libre!
En conclusión: intentaremos responder a una pregunta concreta con el análisis concreto del nivel de madurez de la síntesis de voz y lectores de pantalla libres en los idiomas que se enseñan en nuestros centros.
¿Quién es el destinatario de este artículo? En breve: el protagonista informado. Intentamos que los docentes sean conscientes de las enormes posibilidades que les ofrece la presencia de las TIC en sus aulas. Perseguimos que se forme una opinión fundada sobre medios y herramientas. Algunas de las conclusiones del análisis (si son válidas y convincentes y alguien desea aplicarlas) estarán fuera de su alcance, porque requerirán un trabajo de administración de la máquina o de la red del centro que no le competen. Y es posible que las aplicaciones no estén instaladas ni disponibles en las versiones actuales de las distribuciones. Pero todos sabemos que los protagonistas informados son muy poderosos.
Hasta podemos verbalizar un axioma: lo que es una posibilidad pedagógica para los profesores y alumnos se debe traducir (y normalmente se traduce) en una exigencia para los responsables de las distribuciones.
Empecemos por el principio, debemos tener claro de qué estamos hablando. ¿Qué hace un lector de pantalla? Un complejo conjunto de tareas que con frecuencia es realizado por varias aplicaciones especializadas distintas: seleccionar los fragmentos de texto que queremos escuchar, convertir esos fragmentos a un formato que incluye información sobre cómo debe pronunciarse su síntesis (pensemos que este proceso implica conocimiento sobre los fonemas de una lengua y sobre su entonación o distintos acentos regionales o de clase), convertirlos a un formato de sonido que puede imitar una voz masculina o femenina, enviar el fichero a la salida de audio.
Una advertencia práctica (el que avisa no es traidor): como es habitual en un mundo donde abundan las propuestas más o menos completas, lo que no abunda es la imaginación y el campo de nombres en el que se mueven los autores a la hora de bautizar sus creaciones es bastante reducido. Como tienen que ver con el habla y el discurso, los nombres giran en torno a speakUP, espeak, emacspeak, speech-tools, speech-dispatcher, multispeech, multispeech-up, speechd-up, speechd-el. Como quiera que se refieren a soluciones independientes deberemos tener mucho cuidado para evitar confusiones.
Creo que adivinará el lector a estas alturas que pocas cosas le gustaría más al autor que entrar en el detalle del proceso de síntesis en todos su pasos. Y que adivinará también que al director de la revista, preocupado por los plazos y cuadrar páginas, tales profundizaciones le pueden causar problemas psicosomáticos que debemos humanamente evitar. Dejamos como ejercicio voluntario para el lector interesado la lectura del fichero info de festival, con el glorioso detalle (análisis del texto, marcado de las partes del lenguaje, segmentación por sintagmas, entonación, duración, síntesis, envío al sistema de sonido... qué fascinante todo).
En consecuencia pongámonos en modo esquema: nos limitaremos a señalar que un lector de pantalla no es nada sin un motor de síntesis de texto a voz (TTS son las siglas de Text To Speech); que existen distintos motores de síntesis por software, y que utilizan diferentes formatos de voz incompatibles. ¿Qué motores TTS? Descartamos de entrada epos y freeTTS, el primero porque está orientado a las lenguas eslavas (checo y eslovaco), el segundo porque hace casi dos años que no se actualiza y no nos proporciona nada que no lo proporcionen los restantes motores.
Nos quedan, clasificados por idiomas, los siguientes motores
Seguimos en modo esquema: festival será nuestro motor de preferencia si la máquina permite su uso y si hay voces para nuestra lengua. Un motor no es nada sin voces ¿de qué voces disponemos? Existen voces privativas de alta calidad, que gracias al esfuerzo de la ONCE funcionan en GNU Linux y que la ONCE facilita a sus socios[6]. Vamos a centrarnos, como siempre, en las que nos permiten las libertades esenciales (las voces mbrola limitan algunas libertades, pues prohíben los usos comercial y militar[7]; como bendicen el uso educativo las podremos utilizar a la espera de alternativas plenamente libres de calidad[8 (actualizada)]. Dos formatos de voz son los más importantes: las voces festvox[9] (las que utiliza festival), y las voces de mbrola (para que una voz mbrola pueda ser utilizada por festival es necesario un «adaptador» (wrapper).
Hagamos una nueva lista, esta vez de voces:
¿Cómo saber si funciona festival? Fácil
echo "hola colega" | festival --tts --language spanish --pipe
Si se escucha, y el acento es razonable, habrá funcionado la síntesis TTS. ¿Y el francés, para el que no disponemos de voces festvox?
cat texto_en_francés.txt |/usr/share/cicero/bulktalk.py
Bien, vemos que contamos con un número aceptable de voces. Nuestro problema no es la existencia o no de voces, sino su incompatibilidad y la falta de calidad de muchas. La falta de espacio nos obliga a posponer a la segunda entrega el examen del trabajo que se está realizando en la actualidad para paliar esta situación.
Lectores de pantalla, motores TTS, voces, tenemos las piezas del puzzle, es el momento de ver cómo encajan, iniciamos la exploración de las tecnologías existentes. Comencemos por las soluciones tradicionales, los lectores de pantalla para consola.
Saben lo que nos gustan las paradojas; ¡hemos encontrado una nueva! El lector de pantalla SpeakUP es un producto más del proyecto SpeakUP[10], que reúne aplicaciones de accesibilidad para consola (por ejemplo un reproductor de RealAudio en modo texto o un escáner utilizable desde la consola). ¿En qué consiste el lector de pantalla SpeakUP? Creado por Kirk Reiser and Andy Berdan, se trata de un conjunto de parches al núcleo Linux que proporcionan funciones de accesibilidad desde el inicio del sistema.
Esta característica tiene aspectos positivos y negativos. Por un lado requiere que la distribución incluya de forma generalizada un núcleo ya parcheado, lo cual causa problemas de mantenimiento y actualización: es difícil que una distribución se atreva a mantener una compilación del núcleo que no esté respaldada por un número importante de desarrolladores y de personas que puedan llevar un control de errores o informes de seguridad.
En el aspecto positivo la omni-disponibilidad teórica de la solución la hace inmediatamente utilizable cuando se usan lynx o vim o cualquier otra aplicación que funcione en modo texto.
¿Qué distribuciones incorporan SpeakUP[11]? Janina Sajka mantiene una versión modificada de Fedora (en estos momentos de FC6), SpeakupModified.Org, con iso's descargables y con un almacén de paquetes rpm. En el mundo Debian Shane Wegner ha creado paquetes actualizados con el núcleo 2.6.18, e imágenes para descargar. Hemos instalado en nuestro ordenador la imagen parcheada y la hemos añadido como una opción más en el menú grub. No ha funcionado. ¿Por qué? Porque hay que indicarle el dispositivo que va a realizar la síntesis de voz. SpeakUP está pensado para ser utilizado con sintetizadores de voz por hardware, y el listado de sintetizadores que funcionan se enumera en la página web. Pero para nuestro estudio habíamos decidido utilizar síntesis por software. El procedimiento variará dependiendo de si se ha compilado speakUP como un módulo o directamente en el núcleo; en el caso que nos ocupa deberemos añadir el parámetro speakup_synth=sftsyn a la línea kernel del grub
title 2.6.18-speakup-686 root (hd0,0) kernel /boot/vmlinuz-2.6.18-speakup-686 root=/dev/hda1 ro speakup_synth=sftsyn initrd /boot/initrd.img-2.6.18-speakup-686
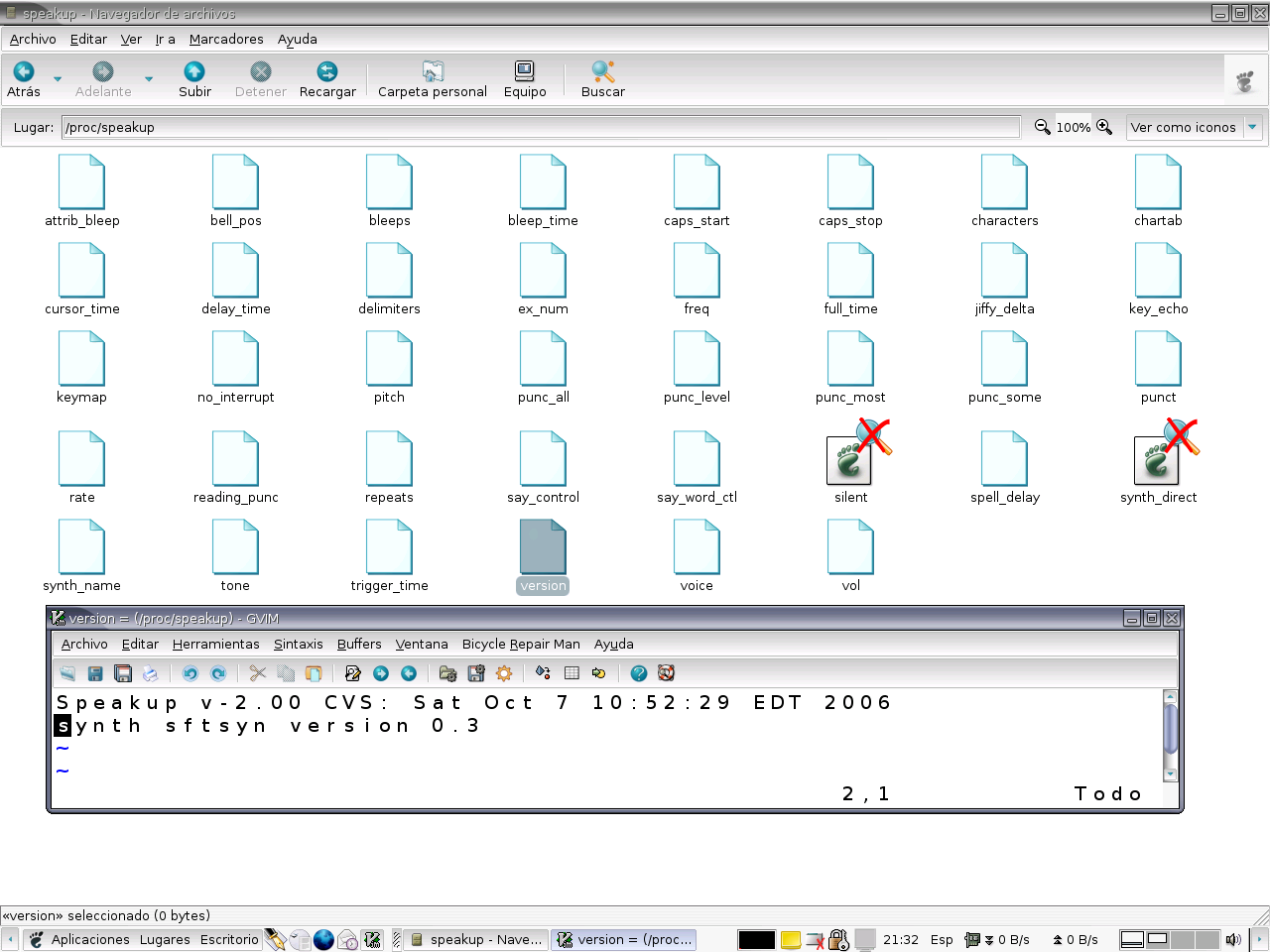
¿Ahora? Tampoco. La síntesis de voz por software no funciona en el inicio (la síntesis por hardware sí). Claro, hay que esperar a la carga de los programas que realizan la síntesis. ¿Cómo sabemos que está activo speakUP? Porque añade todo un subdirectorio con información al directorio /proc (figura 1). Para que nos funcione la síntesis por software debemos instalar dos paquetes adicionales: speech-dispatcher (del que ya hablaremos) y speechd-up (una interfaz entre speakUP y speech-dispatcher creada por los desarrolladores de este último y que permite utilizar motores de síntesis como festival o flite). El instalador Debian de speechd-up crea por nosotros los también necesarios dispositivos /dev/softsynth y /dev/synth; ahora es el momento de ejecutar
sudo speechd-up &
Sigue sin funcionar (los registros muestran errores del sistema de audio «ALSA: Setting channel count to 1», «ALSA: cannot set channel count (Invalid argument)» y «ERROR: spd_audio failed to play the track» tanto si elegimos la salida festival como flite). Aunque el sistema funciona, identifica los textos que debe generar, y sintetiza la voz, no logramos oirlo (ya volveremos sobre las causas, pero en este caso speakUP no tiene la culpa). ¿Fácil, no? Pues no. Todo muy complicado.
Mejor que atosigar y aburrir al pobre lector, es el momento de reflexionar. Nos encontramos ante un sistema que tiene sentido si se utiliza en combinación con un sintetizador por hardware, que en este uso funciona desde el arranque y no nos ocasiona las complicaciones que acabamos de experimentar. De todas formas incluso en este caso tiene dos defectos muy graves para nuestros intereses: el cambio de idiomas y voces sólo puede producirse estáticamente, en la configuración de speech-dispatcher (este cambio además sólo es posible en versiones muy recientes del software, que quizás no estén disponibles en nuestra distribución) y está limitado por el segundo defecto: no reconoce UTF-8, la codificación común de todas las distribuciones modernas.
Tenemos que seguir buscando.
El segundo tipo de solución que vamos a evaluar es un conjunto de desarrollos que, como algunas orquídeas, tienen en común el organismo en el que habitan: emacs. Para comprender cómo funciona emacspeak y el resto de las aplicaciones del título de la sección hay que comprender qué es emacs. Editing MACroS, o el Extensible MACro System, fue el primer paso de Richard Stallman en la construcción del proyecto GNU (sí, el GNU de GNU Linux, el origen de todo). Mucho más que un editor de textos, se trata de un entorno de trabajo escrito en Lisp que ha ido añadiendo funcionalidades hasta merecer el chiste que ya contamos en alguno de los primeros números: emacs sería un buen sistema operativo, lástima que carezca de un buen editor de textos. Es que desde emacs se puede escribir, enviar y recibir correo, se puede navegar por internet y crear páginas web, subir y bajar ficheros por ftp, se puede chatear, jugar, hay atajos y facilidades para escribir código de programación o xml, usar sistemas de versionado... casi cualquier tarea realizable por medio del ordenador se puede llevar a cabo sin salir de emacs, incluso dibujar (todo en modo texto, utilizando caracteres).
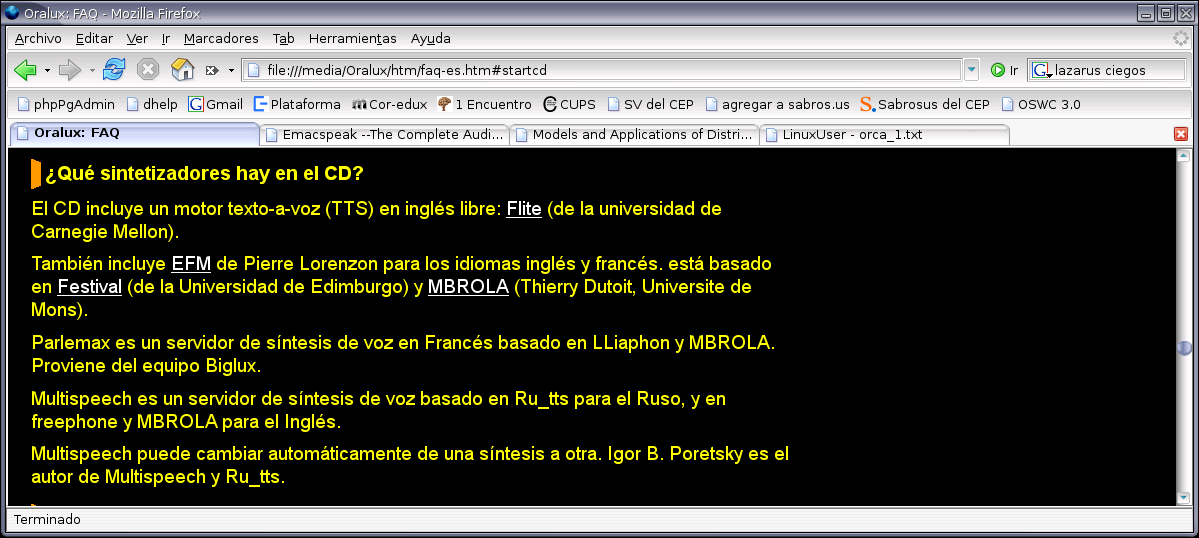
En primer lugar vamos a presentar emacspeak, «el escritorio oral completo»[12]. Pero hemos aprendido de las peripecias anteriores, ¿verdad? No queremos complicadas instalaciones y configuraciones. ¿Cómo podemos ver emacspeak trabajando si los autores de nuestra distribución no lo han preinstalado o si no queremos pelearnos con las profundidades de la administración de un sistema GNU Linux? Hay una solución: ¡usemos un disco life! Sugiero descargar la versión más reciente de la distribución especializada Oralux[13 (actualizada)], en estos momentos las versión 0.7 alpha, y reiniciar el ordenador.
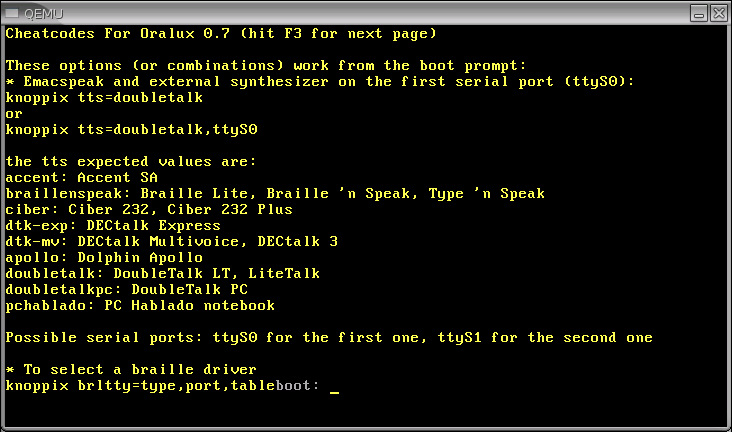
Antes de iniciar el sistema con el disco vivo podemos leer la información html proporcionada en el CD (figura 2). Tras el inicio típico de todos los knoppix (figura 3) escucharemos cantar al gallo Oralux (que se note que es una distribución francesa) y el sistema nos hará una serie de preguntas por escrito y oralmente. En primer lugar nos permitirá elegir el idioma del menú (Do you want this menu in English... en français ... Deutsch... español?, preguntado esto último con un muy fuerte acento inglés de los Estados Unidos), modificar el teclado, seleccionar o no un dispositivo braille, etc. En tanto a lo que nos interesa, el «entorno de interfaz oral de usuario», podremos elegir (supongo que tras que se detecte que no contamos con hardware de síntesis ni braille[14]) entre un escritorio emacspeak o multispeech; elegido este se nos ofrece sucesivamente utilizar multispeech, flite, cicero TTS o DecTalk. Seleccionaremos emacspeak.
Emacspeak, de T. V. Raman, aporta una capa oral sobre emacs. El punto fuerte de la versión 25.0 es el cumplimiento completo de las especificaciones de la W3C sobre las hojas de estilo auditivas. Pero escuchemos a Raman (la siguiente no es una cita literal, sino una paráfrasis adaptada y resumida):
«Emacspeak introduce varias mejoras e innovaciones con respecto a los lectores de pantalla ordinarios; a diferencia de estos, que verbalizan el contenido visual de una pantalla, Emacspeak lee la información subyacente. Por ejemplo cuando otro lector de pantalla se utiliza para leer una aplicación de calendario, el resultado es que el usuario invidente oirá una secuencia sin sentido de números; por el contrario Emacspeak lee la fecha relevante de un modo fácilmente comprensible.
En la interfaz de usuario se utilizan cambios en las características e inflexiones de las voces, combinados con un uso apropiado de iconos sonoros, para crear el equivalente de la estructura espacial, los tipos de letra y los iconos gráficos, tan importantes en la interfaz visual.»
La cita es larga, pero toca cuestiones esenciales. De todos modos no vamos a usar emacspeak directamente. Recordemos que necesitamos responder también al multilingüismo. Una segunda opción, más apropiada para los objetivos de nuestra investigación, es multispeech, de Igor B. Poretsky, «un servidor de habla para emacspeak multilingüe». Permite utilizar hasta seis idiomas: portugués del Brasil, inglés, francés, alemán, ruso y español. Podemos probarlo desde el disco de Oralux (además es compatible con speakUP gracias al paquete multispeech-up).
Vamos por buen camino, ¿verdad? ¿Qué sintetizadores hardware funcionan? El listado que proporciona el paquete emacspeak-ss (los habituales, no vamos a enumerarlos aquí). ¿Y emacspeak y complementos funcionan con voces sintetizadas por software? Sí (el motor flite, con la ayuda de la interfaz eflite). Problema: flite sólo proporciona una voz, y en inglés. ¿Funciona con speech-dispatcher? Podemos decir que sí, gracias a speechd-up, pero como avisan los propios autores «esta interfaz no es en absoluto óptima y sufre de muchos problemas. No obstante es posible que algunos usuarios la encuentren útil». Qué miedo.
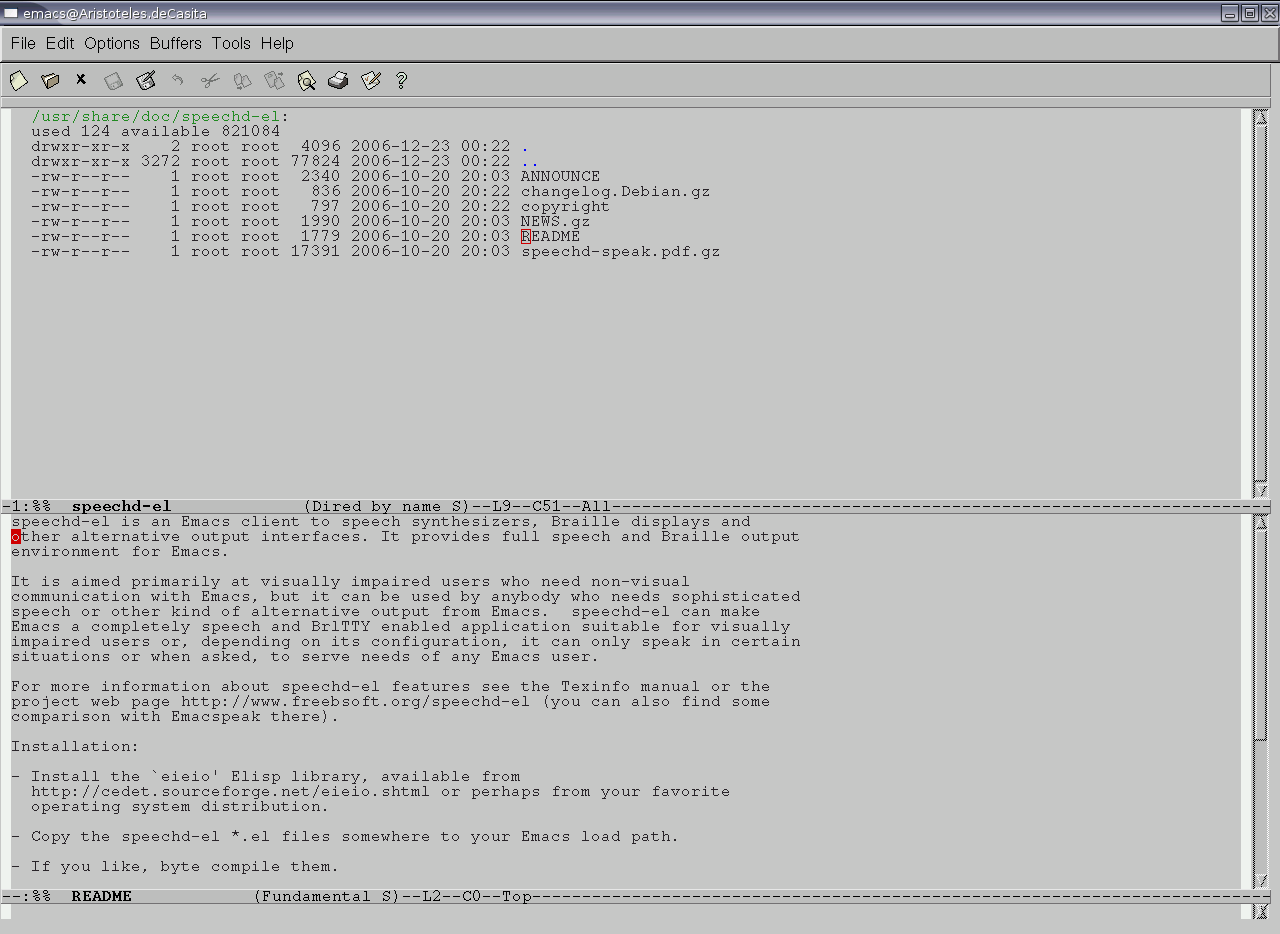
Hay un tercera opción independiente dentro del mundo emacs, que me parece un paso adelante: instalar el paquete speechd-el (y el paquete complementario sound-icons, también preparado por el checo Milan Zamazal). ¿Cómo funciona? Una vez instalado se lanza emacs y se ejecuta
ESC-x speechd-speak INTRO
A partir de ese momento el sistema lee los ficheros que abrimos (la figura 4 muestra el cursor en la línea que acaba de leer), lo que escribimos, las órdenes que ejecutamos...
¿Qué aporta speechd-el? La facilidad de configuración y la integración directa con speech-dispatcher.
¿Hemos terminado? ¿Hemos descubierto la aplicación que buscábamos, funcional, sencilla, multilenguaje? Hay una comparativa entre SpeakUP y Emacspeak en el sitio del proyecto SpeakUP[15]. Recogemos su análisis y lo completamos con las opiniones escuchadas y las propias.
Lo bueno y lo malo de emacspeak, multispeech o speechd-el tienen que ver con su integración con emacs. Aquello que funciona adecuadamente en emacs funcionará de forma brillante en las aplicaciones que le aportan una capa oral; pero qué ocurre con las aplicaciones para consola que no tienen nada que ver con emacs (lynx, vi, centericq?) Sencillamente que tendremos problemas.
Hay una segunda dificultad, más decisiva. El de emacs es un mundo sui generis, diferente al de las interfaces de usuario que se han convertido en estándares. Un usuario avanzado de emacs no se dignará en tocar el ratón: todo se hace más rápido con combinaciones de teclas (lo cual por cierto es positivo para personas que tienen dificultades para manejar el ratón). Pero también es verdad lo contrario: nada está donde los usuarios habituales nos hemos encontrado a encontrarlo ni se llama como se suele llamar. No se abren o guardan ficheros; se visitan, y se guarda el búfer actual. Digamos en conclusión que la curva de aprendizaje tiene una pronunciada cuesta en su inicio. Nada amigable si el grueso de los usuarios viene cargado de hábitos de otros sistemas operativos.
Bien, el amable lector recordará que el autor se permite esporádicamente cinco minutos destructivos. No es grave, y después intenta recomponer los platos rotos. Este es uno de usos momentos.
Si lo que llevamos visto es la respuesta de GNU Linux al problema de la síntesis de voz, sería el momento de empezar a preocuparnos.
1.- No tiene sentido que una aplicación se ocupe de todo el proceso desde el análisis del texto que debe sintetizarse hasta la salida de sonido específica para todos y cada uno de los sintetizadores, sea por hardware, sea de software. Es decir, se nos plantea la necesidad de una interfaz unificada intermedia entre los lectores de pantalla y el software o hardware de síntesis.
2.- El problema del sonido. No nos ha aparecido porque hemos examinado las aplicaciones en situaciones abstractas, pero cualquier usuario de dará de bruces con él: luchan en GNU Linux varios sistemas de sonido (OSS, alsa, esound, arts, jack...) y las aplicaciones pugnan por bloquear los dispositivos de salida. Esto, que sería sólo molesto si a la vez que escuchamos un CD de música queremos jugar a un juego multimedia, es trágico (sencillamente el sistema no va a funcionar) si necesitamos comunicarnos con la máquina por medio del sonido.
3.- La codificación. No está suficientemente documentado (todavía) pero es un problema que es probable que antes o después se nos presente. Las distribuciones modernas han optado (¡al fin!) por utilizar codificaciones UTF-8 de forma predeterminada (ya vimos en los artículos 4 y 5 que eso es lo correcto). Pues bien, los motores de voz actuales (con la excepción de eSpeak) esperan una entrada de 8 bits, a veces exclusivamente iso-8859-1 (el antiguo estándar europeo occidental, también llamado latin1). Es necesario que en algún momento del proceso intervenga un conversor de codificaciones. Por ilustrar el problema con un ejemplo concreto señalemos que festival sólo acepta entradas de 8 bits; la tarea de las funciones presentes en recode.scm, del paquete festival-freebsoft-utils, es llamar a la aplicación externa iconv para realizar la conversión. Y presupone que la entrada va a ser UTF-8.
La fuente de problemas es múltiple: si el sistema espera UTF-8 y enviamos latin1, el conversor de UTF-8 dará error y el proceso no tendrá éxito; si el sistema espera latin1 y enviamos UTF-8 sin la participación de un conversor (es el caso de la mayor parte de los motores utilizados de forma directa) tampoco tendremos síntesis. Pero es que además el problema es estructural: en las lenguas latinas el problema no es más que molesto, pero la síntesis de lenguas en las que los caracteres ocupan más de un byte ahora mismo no es posible.
4.- Supongamos que la interfaz unificada de salida de los sintetizadores existe, sea más o menos perfecta, y un adelanto ha ido apareciendo a lo largo de esta primera entrega: se llama speech-dispatcher. Supongamos también que el problema del sonido se resuelve (veremos cómo en la siguiente entrega). Y que nuestras necesidades sólo tienen que ver con lenguas occidentales, y que con los conversores y un poco de cuidado, y a la espera de mejores voces, nos apañamos. O sabemos idiomas y nos manejamos aceptablemente con una interfaz en inglés. A pesar de todo esto pienso que estaríamos aceptando un fracaso.
Hablo ahora en primera persona, a partir de la experiencia de un usuario que durante años ha preferido el trabajo en la consola por su velocidad y su potencia. Aún en la actualidad tiendo a abrir una terminal a la menor oportunidad (allá cada cual con sus inercias). Sin embargo cada vez tengo más claro que limitar el acceso de las personas con problemas de visión a la consola es reducirlos a un ghetto. Por mucho que avancen las aplicaciones para consola, el grueso del desarrollo se está realizando en proyectos como Gnome y KDE. Nuestro desafío, y el desafío de la comunidad, es la accesibilidad para todos de aplicaciones como firefox u OpenOffice.
No necesitamos una aplicación adaptada, accesible en consola, para cada tarea, sino que las aplicaciones de uso general sean plenamente accesibles. Es un enfoque radicalmente distinto; implica que de una vez seamos capaces de analizar de forma abstracta la interfaz de usuario y de pensar que no tiene porqué ser exclusivamente gráfica, que por ejemplo el concepto de iconos puede ser gráfico u auditivo, o que al fin se utilice adecuadamente el html (o el xml del Open Document Format) como lo que es desde su creación, un lenguaje de marcas con carga semántica, leíble de distintos modos según la hoja de estilos que se utilice.
¿Cómo se resuelven los problemas planteados? ¿Nos queda alguna esperanza? No se pierdan la continuación de esta apasionante serie de artículos.
[1] Linux Magazine guarda la versión pdf de todos los artículos de la sección de educación. Los citados se pueden descargar en los enlaces http://www.linux-magazine.es/issue/06/ y http://www.linux-magazine.es/issue/07/. Asímismo el autor aloja versiones accesibles (en html) en http://people.ofset.org/jrfernandez/edu/n-c/a11y_1/index.html y http://people.ofset.org/jrfernandez/edu/n-c/a11y_2/index.html.
[2] Digamos mejor clave, condición sine qua non para que una distribución sea educativa, porque una distribución que no atiende a la diversidad no será nunca una distribución educativa.
[3] Festival (http://www.cstr.ed.ac.uk/projects/festival/) es un proyecto de la Universidad de Edimburgo. En estos momentos la versión incluida en Debian es la 1.4.3-17.2, bastante anticuada (por citar un ejemplo no permite utilizar las voces nuevas en el formato MultiSyn). En las páginas de partes de error hay hace tiempo un aviso para que se cree el paquete de la versión 1.95 (http://bugs.debian.org/327541); sin embargo Alan W Black puso a disposición de todos una versión 1.96-beta (http://www.speech.cs.cmu.edu/awb/fftest/festival-1.96-beta.tar.gz) hace ya casi dos años. En este aspecto no se está al día en absoluto. Lamentamos no poder analizar con algo de detalle el motor de voz; simplemente diremos que quien lo utilice debería instalar también festival-freebsoft-utils (seguimos en modo esquema: leer el fichero info).
[4] http://espeak.sourceforge.net, un motor plenamente libre (incluido en Debian). Hay un análisis muy interesante de Nickolay V. Shmyrev en la lista de festival-talk (6 de septiembre de 2006).
[5] http://tcts.fpms.ac.be/synthesis/mbrola.html. Hay paquetes Debian preparados por Igor B. Poretsky y Gilles Casse, en el almacén de Oralux.
[6] Loquendo (http://www.loquendo.com/) o TTSynth, el antiguo IBM ViaVoice (http://www.ttsynth.com/)... hay un conjunto de enlaces, privativos o libres, en http://wiki.tiflolinux.org/index.php/Sintesis_de_voz_en_linux_listado. En la próxima entrega escribiremos acerca de las importantes aportaciones de la ONCE al mundo del software libre.
[7] La licencia de mbrola y sus voces puede leerse en http://tcts.fpms.ac.be/synthesis/mbrola.html.
[8] En el próximo número trataremos con el detalle que merecen los proyectos de creación de voces
libres para el castellano y el catalán.
[10] El proyecto SpeakUP: http://fl.linux-speakup.org/; la página del lector de pantalla SpeakUP: http://fl.linux-speakup.org/speakup.html. Hay un Speakup HOWTO en http://www.tomass.dyndns.org/~stivers_t/Speakup-HOWTO/Speakup-HOWTO.html (de Thomas Stivers, 2004) y un The Speakup User's Guide For Speakup 2.0 and Later, de Gene Collins, de 2005 (http://fl.linux-speakup.org/spkguide.txt).
[11] SpeakupModified: http://speakupmodified.org/. Núcleos para Debian: http://people.debian.org/~shane/speakup/kernel/.
[12] http://emacspeak.sourceforge.net/. Raman se ha molestado en enumerar un listado de tareas realizables: http://emacspeak.sourceforge.net/applications.html. Fuentes de multispeech: ftp://ftp.rakurs.spb.ru/pub/Goga/projects/speech-interface/current (hay paquetes en el almacén de Oralux).
[13] Oralux: http://oralux.org/. Casi tan interesante
como la distribución es su almacén de paquetes Debian
deb http://oralux.net/packages unstable main non-free contrib.
Oralux no es la única distribución orientada hacia las personas con problemas de visión, pero
entiendo que es la que más está contribuyendo (gracias a Gilles Casse) a las distribuciones
generalistas, puesto que como hemos visto no se limita a seleccionar aplicaciones ya existentes,
sino que crea sus paquetes propios y se esfuerza porque esos paquetes lleguen en concreto a
Debian. Una alternativa hispana sería Lazarux, derivada de Ubuntu, presentada por
quetzatl en
http://www.tiflolinux.org/?q=node/39
(la 2.0-4 es de agosto del 2006). Se puede descargar por el momento en
http://www.grupomads.org/download/
(grupo que al parecer está relacionado con la Universidad de la Coruña).
«This mail for informing you that the Oralux CD, as it is, will be no more developed. Oralux 0.7 will remain online for persons wishing to have speech, possibly in their own language, in text-based environments. The Oralux live CD project started in spring 2003; these releases offered some of the solutions known by English speaking GNU/Linux visually impaired users. I hope that this CD helped some new users discover these solutions and finally eased their transition to more general distros. During these years, the Oralux project proposed enhancements, patches or fixes to accessibility projects such as Emacspeak, Lliaphon, Multispeech, Speechd-up, Speakup, and Yasr. Several softwares were also started: mcvox, an accessible Midnight Commander, Tengoo, a text transcoder. The 0.7 alpha release offers six spoken languages, its menu or documents have been kindly translated in several of these languages. The Oralux live CD has been downloaded from our mirrors or sent by postal mail for free. Today, general distro such as Ubuntu Feisty offers eSpeak, the multilingual speech synthesis. We would wish to contribute now to others features.»
[14] Según la documentación, un tanto obsoleta, las opciones son ¡speakUP, preinstalado sin sudor ni lágrimas!, emacspeak, y un tercero, yasr. Yasr, Yet Another Screen Reader, es un lector de pantalla escrito por Mike Gorse, descrito como «ligero y portable»: http://sourceforge.net/projects/yasr/; hay paquete Debian, de Mario Lang, y versión modificada por Gilles Casse.
[15] Concretamente en http://fl.linux-speakup.org/faq.html.