| 4. How to share translation memories? | ||
|---|---|---|
 |  | |
| 4. How to share translation memories? | ||
|---|---|---|
| | | |
Let's get a bit more technical: according to the EAGLES-I project a Translation Memory is
a multilingual text archive containing (segmented,
aligned, parsed and classified) multilingual texts,
allowing storage and retrieval of aligned multilingual
text segments against various search conditions.
The idea is that some phrases are repeated continuously in different texts (e.g. “Save to file”), and to provide a technology to use the already correctly translated version to save time and guarantee quality in the translation. Good translation memories contribute to the quality of translations in two ways: their coherence and accuracy.
The industry standard for the exchange of translation memories is LISA's TMX (Translation Memory eXchange). «OSCAR» (Open Standards for Container/Content Allowing Re-use) is the LISA Special Interest Group responsible for its definition.
«The purpose of TMX is to allow easier exchange of translation memory data between tools and/or translation vendors with little or no loss of critical data during the process.»
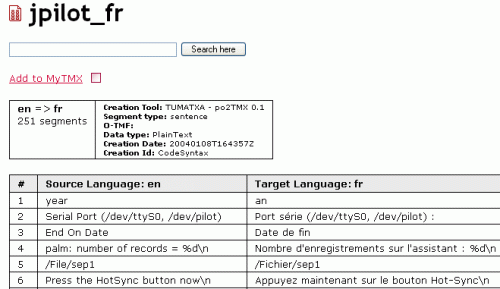
Here's an example of a French to Spanish translation.
<tu tuid="1">
<note>
#: index.docbook:2
</note>
<prop type="x-Domain">Software UI</prop>
<prop type="x-Project">wims.xml 1.1</prop>
<tuv lang="fr">
<seg>
Prise en main de WIMS
</seg>
</tuv>
<tuv lang="es">
<prop type="x-LastTranslator">
Juan Rafael Fernández García
-juanrafael.fernandez@hispalinux.
"Language-Team: Spanish -es@li.org-</prop>
<seg>
Iniciación a WIMS
</seg>
</tuv>
</tu>
How to use it in free software? . kbabel can import TMX TMs
OmegaT works with version 1.1.
A great idea: sharing TMs (TMX and po) online, TuMatXa.
| | | |
| 3. The problems with PO |  | 5. How can teams cooperate better? |