Con un poco de filosofía por compañera, expondremos el modo en que podemos satisfacer las necesidades de nuestros compañeros profesores de otras lenguas, y de los alumnos inmigrantes, en materia de interfaz de usuario y de entrada de caracteres. Por Juan Rafael Fernández García.
Este documento tiene su origen en el artículo publicado por primera vez en el número 4 de la revista Linux Magazine, de abril de 2005, con el nombre de «Otros idiomas, otros caracteres». El artículo puede descargarse en el enlace http://www.linux-magazine.es/issue/04/, y está publicado por contrato bajo licencia Creative Commons Reconocimiento-NoComercial-CompartirIgual 2.0 (-sa-by-nc 2.0).
El fenómeno de la multiplicidad lingüística (la cuestión babélica: no hablamos una lengua, ni media docena ni veinte ni treinta; se piensa que en la actualidad se practican de cuatro a cinco mil) es un dato de la evolución humana que debe ser explicado no como una desviación sino como esencial a nuestra especie, relacionada con su forma de adaptarse a la realidad (la inteligencia) y creatividad. Como escribía Steiner[1], «Cada lenguaje humano traza un mapa del mundo de manera diferente. Cuando un idioma muere, con él muere un mundo posible». Muchos sueñan con un único idioma universal, que simplificara los problemas de comunicación, eliminara la necesidad de traductores, disolviera en el vacío las interpretaciones. Ahí está la clave: es como reducir la riqueza de las cocinas del mundo a la sutileza de un burger.
Pero tranquilos, este es un documento práctico. Pretende responder a un problema real, de profesores y alumnos: vamos a aprender a internacionalizar nuestro ordenador. La solución pasa por enfrentarse -justifica el párrafo anterior- a la tentación de uniformismo predominante. Se ha dado el caso que algunos de los creadores de las distribuciones regionales que utilizamos olvidan que nuestras necesidades no son monolíticas ni raquíticas; que aunque parezca mentira el griego clásico es una lengua muerta que sustenta nuestra filosofía y nuestro lenguaje científico; que tenemos cada vez más alumnos árabes, eslavos, chinos, que tienen derecho a leer sus propios alfabetos, y que los profesores de idiomas queremos una inmersión en el idioma que incluye ---cómo no--- el entorno, los mensajes, los menúes. Veremos cómo se hace esto.
El proceso tiene tres partes independientes: indicarle al sistema operativo el idioma que queremos para la interfaz, elegir un tipo de letra que tenga los caracteres adecuados para el idioma seleccionado y configurar un mapa de teclado que los permita introducir los caracteres propios del idioma que pretendamos escribir.
En GNU Linux el sistema de internacionalización y localización se basa en el modelo de los «locales». ¿Cómo funciona esto? Cuando se instala un programa internacionalizado (preparado para su traducción a distintos idiomas; no es necesario reescribir el programa en cada uno de ellos) se instalan también los mensajes en todos los idiomas a los que se ha traducido; cuando se ejecuta, el sistema operativo lee la variable de entorno (más exactamente un conjunto de variables) correspondiente al locale y muestra los mensajes correspondientes. Los locales permiten definir cosas como el tamaño de papel más usado en un país, el símbolo de moneda, o el criterio con el que se ordenan alfabéticamente las palabras.
Es muy probable que los autores de la distribución que usted utiliza hayan predefinido un locale, seguramente es_ES@euro (abreviatura de es_ES.iso8859-15), para los usuarios españoles y textos en español. Estas son dos decisiones independientes que no debemos confundir: la primera se refiere al idioma en que la máquina (los programas, los mensajes de error, etc.) se dirigirá a nosotros (si existe la traducción correspondiente al mensaje; incluso se puede distinguir español de España, es_ES, de las restantes variedades del castellano: es_AR, es_CO...; y al revés, ca_ES, ga_ES...), qué carácter mostrará en pantalla cuando pulsemos la tecla que tiene pintada una «ñ» y cuestiones similares (como que el tipo de letra que sale por la pantalla contenga la «ñ» y que el programa de impresión pueda enviársela a la impresora). La segunda se refiere a la codificación en que están los textos si no se indica lo contrario (ver el cuadro 1). Poner como locale es_ES@euro equivale a pedir que los mensajes estén en español, con criterio de ordenación alfabética, signo de moneda, etc. correspondiente a España, y utilizando determinada codificación, la latin9, que incluye el signo del euro.
Para el castellano de España podrían utilizarse los locales es_ES (alias de es_ES.iso8859-1), es_ES@euro o es_ES.UTF-8. ¿Cuál es preferible? Como casi siempre, depende; la mayor parte de las distribuciones Linux están abandonando las codificaciones antiguas en favor de UTF-8 porque es manifiestamente superior. Pero se nos presentan varios problemas: en primer lugar no todos los programas están adaptados para funcionar correctamente con un locale UTF-8, por ejemplo el útil y conocido mc no va bien... por otro lado nuestros ficheros de texto deberán ser convertidos a la nueva codificación, y también los nombres de los ficheros y directorios, si hemos cometido el error de utilizar caracteres no ascii al guardarlos, o recibido archivos de nuestros amigos usuarios de Windows; ¿y qué pasa en una máquina donde conviven usuarios que han elegido utilizar codificaciones diferentes? En este sentido los usuarios de Windows XP lo tienen más fácil: quien sea ha tomado la decisión por ellos, sólo existe UTF-16, problema resuelto.
En primer lugar averigüemos el locale en el que estamos trabajando. Basta con ejecutar la orden locale en una terminal:
[Mi_maquina]$ locale LANG=es_ES.UTF-8@euro LC_CTYPE=``es_ES.UTF-8@euro'' LC_NUMERIC=``es_ES.UTF-8@euro'' LC_TIME=``es_ES.UTF-8@euro'' LC_COLLATE=``es_ES.UTF-8@euro'' LC_MONETARY=``es_ES.UTF-8@euro'' LC_MESSAGES=``es_ES.UTF-8@euro'' LC_PAPER=``es_ES.UTF-8@euro'' LC_NAME=``es_ES.UTF-8@euro'' LC_ADDRESS=``es_ES.UTF-8@euro'' LC_TELEPHONE=``es_ES.UTF-8@euro'' LC_MEASUREMENT=``es_ES.UTF-8@euro'' LC_IDENTIFICATION=``es_ES.UTF-8@euro'' LC_ALL=es_ES.UTF-8@euro
¿Dónde se ha definido este locale? Hay diferentes posibilidades: si el administrador de la máquina quiere fijar un locale común para todos los usuarios y todos los entornos (lo que es frecuente en nuestras distribuciones) puede hacerlo en /etc/environment; basta lo siguiente, puesto que LC_ALL es la orden que engloba a las órdenes de detalle:
export LC_ALL=es_ES.UTF-8@euro
export LANG=es_ES.UTF-8@euro
Si se quiere independizar el trabajo en consola del trabajo en X el lugar es /etc/default/gdm. Si finalmente un usuario quiere modificar su entorno puede hacerlo de forma general en ~/.bash_profile o de forma granular en el directorio ~/.xsession.d. O puede hacerlo programa por programa, utilizando variables de entorno.
Un ejemplo sencillo vale más que mil explicaciones. date es un programa que devuelve la fecha y la hora. Para un usuario que no ha configurado sus locales o que ha elegido el locale POSIX (C) la salida sería igual a la de un programa no internacionalizado, con mensajes probablemente en inglés:
[Mi_maquina]$ LC_ALL=C date
Wed May 8 20:46:09 CEST 2002
Para ver la salida en francés basta con usar
[Mi_maquina]$ LC_ALL=fr_FR date
mer mai 8 20:46:31 CEST 2002
Por supuesto que no hay que estar repitiendo la variable de entorno cada vez que se ejecuta un programa si el locale está definido en el sistema o en los ficheros de configuración del usuario. Como hemos elegido un locale español la orden nos responderá en español
[Mi_maquina]$ date
mié may 8 20:46:22 CEST 2002
Ahora estamos en situación de comprender mi ataque anterior contra el monolitismo. Existe un programa, localepurge, que se encarga de borrar sistemáticamente los mensajes y ficheros de ayuda de los idiomas que el administrador de la máquina piensa que no va a utilizar. Y el administrador de estas máquinas puede pensar, él solito, que sólo se va a necesitar el castellano. Borra tan feliz los mensajes en tagalo, de acuerdo, en chino de HongKong, en rumano, pase, pero también en italiano, en francés... antes de continuar, antes de instalar el próximo programa o hacer el siguiente apt-get upgrade tenemos que comprobar si tenemos instalado localepurge y cómo está configurado. ¿Cómo? Con la orden
[Mi_maquina]# dpkg-reconfigure localepurge
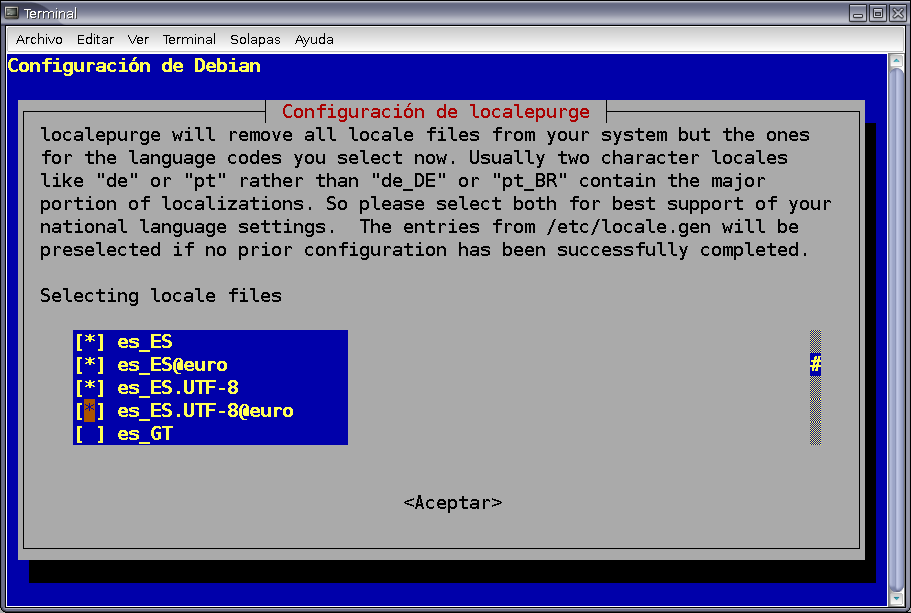
En la figura 1 podemos ver cómo se seleccionan los distintos locales válidos para el castellano. De acuerdo, pensamos, ya podemos ver los mensajes en los idiomas que necesitan nuestros alumnos. Pues no: los mensajes estarán ahí, pero vamos a ver sus equivalentes en inglés porque los locales tienen que estar creados en el sistema. O sea que abrimos la terminal que seguro que habíamos cerrado, volvemos a cambiar a root y creamos los nuevos locales
[Mi_maquina]# dpkg-reconfigure locales
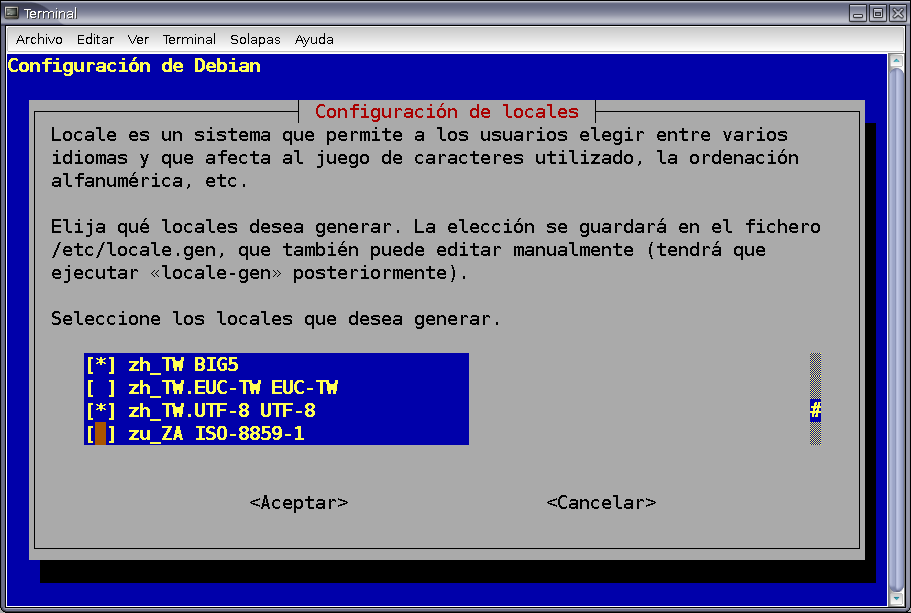
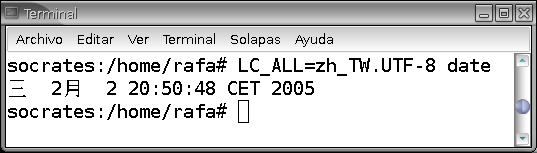
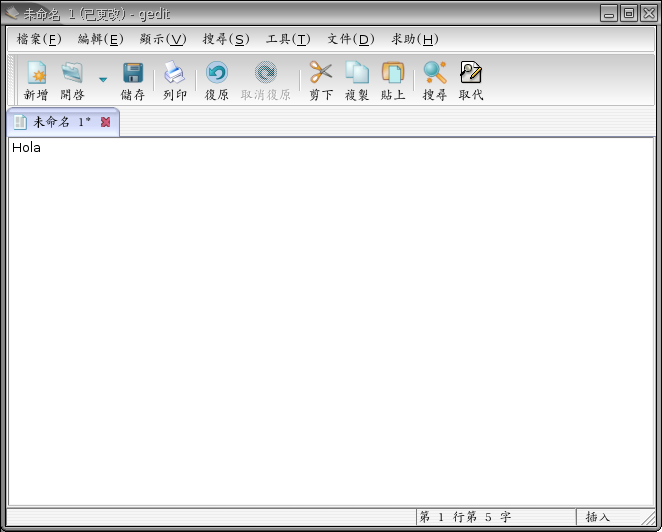
Para este documento (figura 2) vamos a crear en mi ordenador los locales necesarios para mostrar mensajes y escribir en chino de Taiwan, porque responde a una petición real, de un compañero con dos alumnas chinas. En la figura 3 podemos al fin ver la salida de la orden date en chino tradicional. Y a partir de ahí podemos lanzar cualquier programa y obtendremos el menú y los mensajes en chino. ¿No se me cree? Pues ahora abrimos este mismo editor con los menúes en chino (figura 4). Podemos crear una cuenta para las alumnas, configurarla con los locales apropiados, y tendrán la interfaz en chino.
¿De verdad es tan sencillo? Depende de la distribución y del administrador. Por un lado han debido instalarse los paquetes necesarios (las ayudas de OpenOffice, la documentación de KDE...), pero también se nos olvida un detalle esencial: los tipos de letra. Si los tipos disponibles no incluyen el carácter que queremos mostrar, será imposible mostrarlo.
Supongamos que queremos que la máquina se siga dirigiendo a nosotros en español (no vamos a tocar los locales ahora) pero queremos leer y escribir en otro idioma y otro alfabeto. Y luego queremos poder imprimirlo. Vale, es cuestión de tres cosas: tipos de letra, un locale UTF-8 y configuración de la entrada por teclado.
Deberemos utilizar tipos de letra que contengan los caracteres de los idiomas que queremos poder representar. Más concretamente y como explicamos necesitamos tipos de letra unicode, iso-10646-1.
Históricamente el tema de los tipos de letra ha sido un problema complicado en Linux: no había una forma unificada de instalar y configurar nuevos tipos, porque los programas que conforman la distribución tenían orígenes distintos y habían implementado soluciones diferentes y propias. La mayoría de las aplicaciones, incluidas las X, utilizaban tipos bitmap; tardó bastante tiempo en aparecer un sistema de gestión coordinado de tipos de letra y la posibilidad de utilizar los tipos vectoriales. Afortunadamente esto ya no es verdad, y la gran mayoría de los programas que utilizamos (todos los programas de KDE3 y Gnome2, OpenOffice y Mozilla) reconoce el esquema de configuración fontconfig.
¿Cómo se añade un tipo? En primer lugar, debemos copiar el fichero Type1 o TrueType a alguno de los subdirectorios recogidos en /etc/fonts/fonts.conf (o añadir otro en /etc/fonts/local.conf). Seguidamente reiniciaremos las cachés de tipos ejecutando fc-cache:
[root@Máquina]# dpkg-reconfigure fontconfig
Abriendo el menú desplegable de fuentes en oowriter veremos que ya tenemos disponible la nueva letra. Vale, pero ¿cuántos de los tipos instalados o disponibles son unicode? Ya se sabe que los linuxeros viejos tenemos querencia a las terminales: xlsfonts | grep iso10646-1 nos las lista; xlsfonts | grep iso10646-1 | wc -l los cuenta por nosotros; en mi portátil devuelve 914.
No obstante no hemos avanzado mucho. ¿Cuáles son, de dónde los descargo?, se preguntará el lector interesado. Antes de seguir debemos romper un mito: un tipo unicode no es un tipo universal, sino un tipo ordenado de determinada manera, con índices que siguen el estándar unicode. Un tipo unicode puede tener un sólo glifo (representaciones concretas de los caracteres, que son entes abstractos); necesitamos tipos que tengan glifos para los caracteres de los idiomas con los que trabajamos. Hay tipos unicode muy completos, que intentan cubrir el máximo de escrituras; otros tienen un objeto específico, cubren el griego clásico, las runas, el cheroqui o el gujarati.
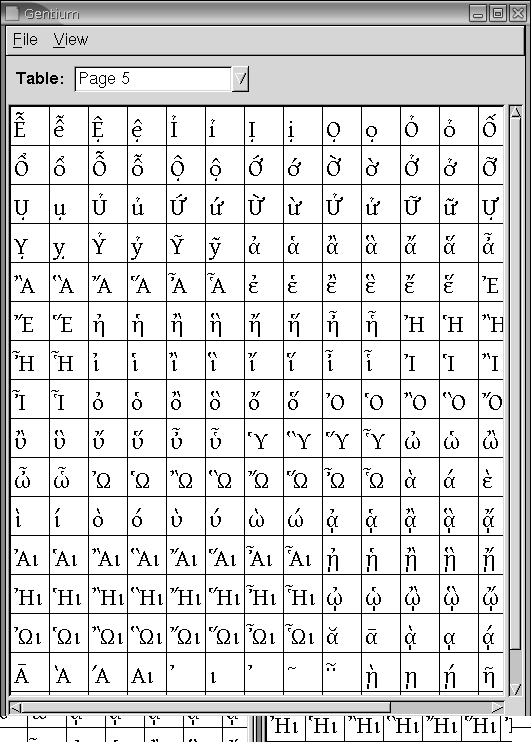
Hace tiempo que GNU Linux puede utilizar los tipos TrueType, y desde hace más tiempo admite los tipos Type1 de Adobe. Si somos propietarios legítimos de estos ficheros podemos reutilizarlos. gfontview nos informa del número de glifos de cada tipo, y nos los muestra por páginas (en la figura 5 tenemos un ejemplo). Existe un paquete de tipos propiedad de Microsoft que puede instalarse si no libre al menos gratuitamente: msttcorefonts, que aporta las conocidas Andale, Arial (1320 glifos), Comic, Verdana. El paquete ttf-freefont incluye entre otras la Free Serif, con 3513 glifos. gentium aporta 1699. Titus, 9779. Los tipos creados para las lenguas orientales son necesariamente grandes: «AR PL KaitiM Big5» (paquete ttf-arphic-bkai00mp) y «AR PL Mingti2L Big5» (paquete ttf-arphic-bsmi00lp) tienen ambas 14148 glifos, «Kochi Gothic» y «Kochi Mincho» 15365. Y faltan las gigantes: Code 2000, 62891; Bitstream Cyberbit, 29934. Busque en su distribución porque la mayoría están empaquetadas. Y siga los enlaces de http://eyegene.ophthy.med.umich.edu/unicode/fontguide/ si tiene necesidades especiales (¿escribe usted textos en cretense o en devanagari?).
¿Por qué las alumnas no podían ver páginas en chino? Porque faltaban los tipos de letra. Un pequeña investigación puede ser instructiva (mejor enseñar a pescar que regalar un pescado). Vamos a averiguar los ficheros de tipo de letra que abre firefox cuando muestra páginas con distintas codificaciones; para ello visitaremos las distintas versiones de la página inicial del proyecto Debian. Utilizaremos lsof. Supongamos que el número de proceso de firefox cuando tenemos abierta la página es 6554 (se obtiene, claro, con ps); los ficheros ttf que utiliza el proceso se filtran así
lsof +c 0 -p 6554 |grep ttf
La versión en español tiene la codificación iso8859-1. La salida es (simplificada por cuestión de espacio) VeraSe.ttf, Vera.ttf, VeraBd.ttf y VeraSeBd.ttf. Para textos en latin1 (y latin9, añado yo) nos basta el tipo ttf-bitstream-vera en sus distintas variantes negrita, serif...
He buscado una página codificada en utf-8; hay pocas, usaremos esperanto. Nos devuelve Vera.ttf, VeraSe.ttf, Arial_Bold.ttf, Arial.ttf, VeraSeBd.ttf y Times_New_Roman.ttf. Vemos que para el esperanto ya no es suficiente el tipo vera y hace uso de los tipos proporcionados por el paquete msttcorefonts.
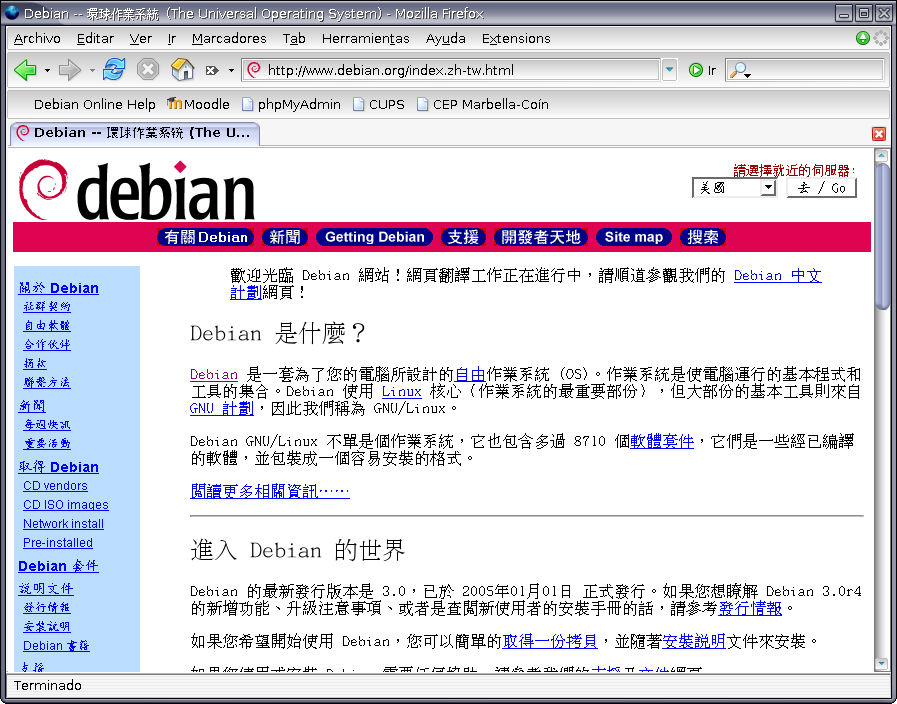
¿Qué ocurre si abro http://www.debian.org/index.zh-tw.html, en chino tradicional (Big5) (figura 6)? Se abren VeraSeBd.ttf, Arial.ttf, VeraSe.ttf, Cyberbit.ttf, Arial_Bold.ttf, Vera.ttf. Claro, los caracteres chinos no están en los tipos anteriores y sí en cyberbit (o en los arphic si se busca una fuente enteramente libre).
Cuadro 1
| Cuadro 1: Códigos, códigos, códigos |
|
En un principio todo era simple: en los ordenadores sólo se escribía en inglés de Estados Unidos, para el que bastan muy pocos caracteres; se decidió que con siete bits bastaba, lo que nos da 128 caracteres, incluidos códigos de control. Cuando la informática se internacionalizó surgieron dos problemas: por un lado la necesidad de traducir los programas, pero también la obligación de mostrar e introducir los caracteres de las otras lenguas. Fue necesario estandarizar codificaciones y los programadores y autores de sistemas operativos debieron buscar soluciones. Se optó por utilizar un byte completo, lo que permitió definir 256 caracteres. Así había una codificación para Estados Unidos, otra para la Europa Occidental, para el griego, el ruso, el japonés... Esto lo hemos vivido todos, recordemos los problemas de los caracteres extraños que padecimos cuando pasamos de guardar nuestros datos en DOS a guardarlos en Windows 95: técnicamente hablando pasamos de usar cp850 ó cp437 a usar windows-1252. En el mundo Unix se actuó de forma similar: los usuarios de todo el mundo tenían que utilizar distintas extensiones de ASCII específicas para cada idioma. Las más usadas eran ISO-8859-1 (también conocida como latin1; una modificación fue ISO-8859-15 ---latin9 ó latin0---, creada para incorporar el símbolo del euro «€») y ISO-8859-2 en Europa, ISO 8859-7 en Grecia, KOI-8 / ISO 8859-5 / CP1251 en Rusia y países de alfabeto cirílico, EUC y Shift-JIS en Japón, BIG5 en Taiwan, etc. Esto hacía difícil el intercambio de ficheros y los programadores tenían de preocuparse de las pequeñas diferencias entre cada una de las codificaciones; habitualmente la internacionalización era incompleta o deficiente, porque era raro que los desarrolladores comprendieran o usaran estas escrituras. Pronto se comprobó que esta solución es incorrecta: ata la codificación que elige el usuario para su sistema a la de los textos que puede leer y escribir (¿por qué un profesor español no puede escribir textos en griego?), rompe la internacionalización en pequeños fragmentos inconexos difícilmente compatibles, obliga a crear tipos de letra para cada codificación... Se hizo evidente que era necesario separar la localización de la codificación, y a finales de los años 80 se impuso la idea de una codificación universal, unicode. Unicode asigna (o asignará, es un esfuerzo no terminado) de forma unívoca una posición y un nombre a cada uno de los caracteres de las distintas escrituras del mundo. Los principales sistemas operativos han adoptado el estándar unicode en alguna de sus concreciones: Apple estuvo en su génesis, Windows XP ha generalizado el uso de UTF-16. La forma de escribir unicode en GNU Linux se llama UTF-8, y los gurús juran que es superior y más eficaz que UTF-16. ¿Por qué unicode es superior? Porque independiza la cuestión de configurar el idioma del usuario del número de caracteres que puede escribir y leer en su configuración. Antes, si elegíamos un locale ruso difícilmente podríamos ver caracteres árabes; ahora podemos ver varios miles de caracteres, y podemos introducirlos con herramientas que nos permitan mapear el teclado. Descendamos a los ejemplos para no perdernos: el carácter «n» es el US-ASCII 110, en hex. 6e; nuestra «ñ» sencillamente no existe en esa codificación, no puede representarse. En latin1 (iso-8859-1) la «ñ» ocupa la posición 241 (F1 en hex.), pero no se puede representar el euro. En latin9 (iso-8859-15) la «ñ» ocupa la misma posición y el euro la 164 (hex. A4). En unicode la «n» es la «U+006E LATIN SMALL LETTER N» (los primeros caracteres equivalen exactamente a los ascii; es una de las ventajas que señalan los gurús de los que hablábamos: un texto ascii es un texto correcto en utf-8) , la «ñ» es la «U+00F1 LATIN SMALL LETTER N WITH TILDE» y el signo del euro es «U+20A0 EURO-CURRENCY SIGN». Y tenemos además todos los caracteres de las principales lenguas, y símbolos matemáticos, y notas musicales... |
[1] George Steiner, Después de Babel. Fondo de Cultura Económica.